Nachdem wir im
ersten Teil die IBM Support Assistant Workbench installiert haben, wollen wir uns diesmal ansehen wie man den Healthcenteragent in die JVM von Notes installiert und welche Einstellungen man anpassen muss, damit das Profiling funktioniert.
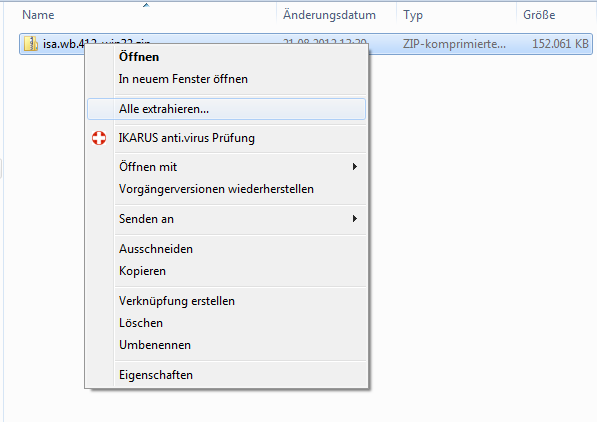
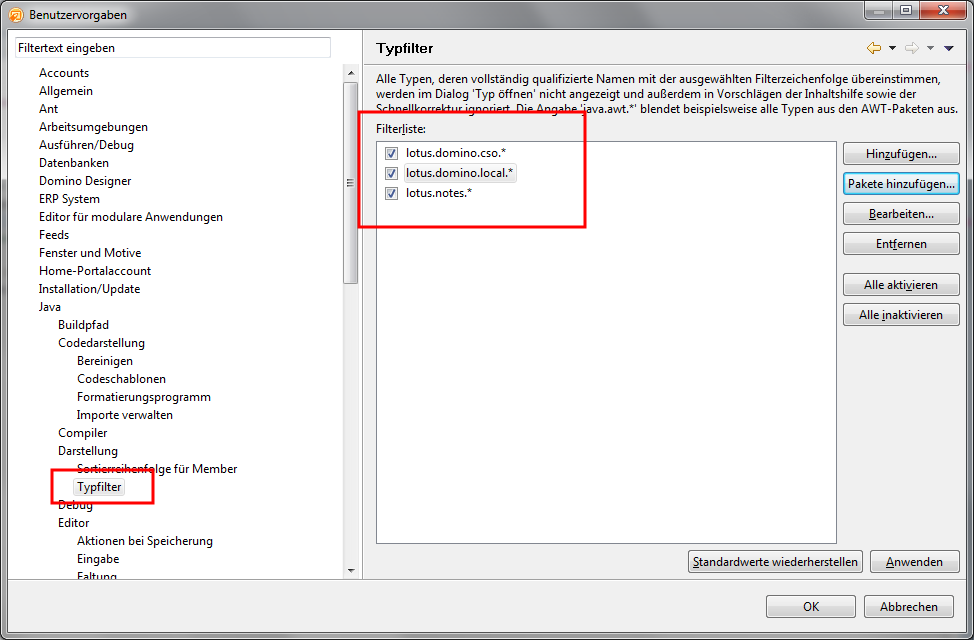
Als erstes muss man den Healthcenteragent aus der Workbench extrahieren. Man ruft dazu das Hilfecenter auf.
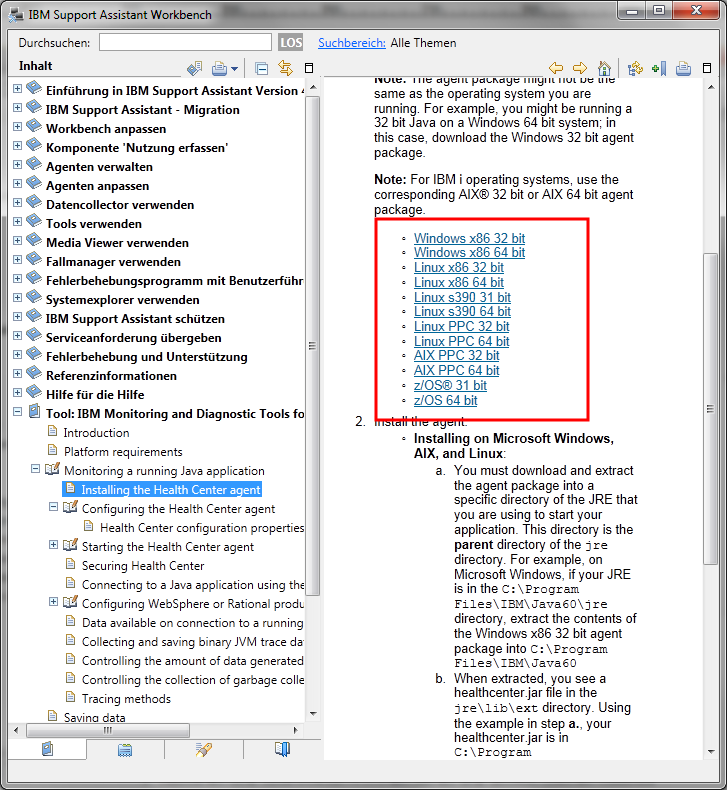
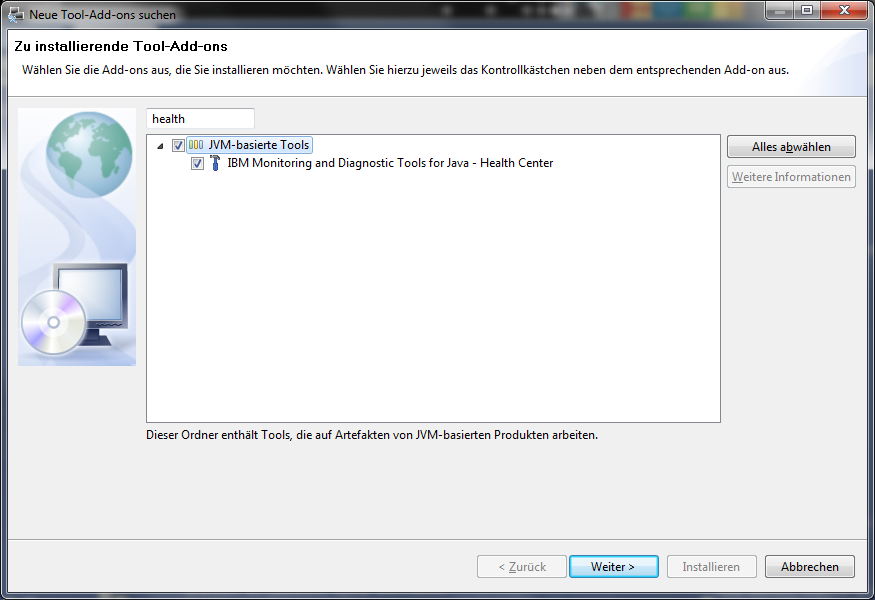
In diesem wählt man in der linken Seitenleiste zuerst den Eintrag "Tool: IBM Monitoring and Diag..." dann den Punkt "Monitoring a running..." und dann "Installing the Health.." Auf der rechten Seite wird dann eine Liste mit den Agents angezeigt. Für Lotus Notes unter Windows sollte man den "Windows x86 32 bit" auswählen.
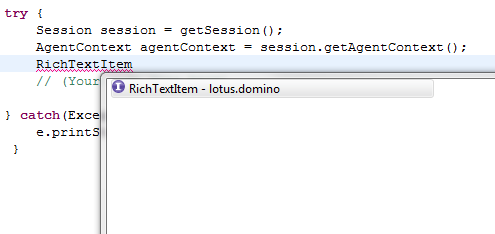
Nach dem Anwählen des Agent erhält man ein Zip File, dass man entpacken muss. In dem Zipfile befindet sich ein Ordner "jre". Den Inhalt dieses Ordners muss man in das jvm Verzeichnis von Notes einkopieren. Unter Windows befindet sich dieses standardmäßig in "C:\Program Files (x86)\IBM\Lotus\Notes\jvm". Eventuell ist schon eine ältere Version des Healtcenteragent installiert. Diese kann problemlos überschrieben werden. Falls man mit eingeschränkten Rechten arbeitet, muss man eventuell noch das Administratorpasswort eingeben. Wichtig ist, dass der Inhalt des jre Verzeichnis aus dem zip wirklich genau in die Verzeichnisstruktur der jvm passt.
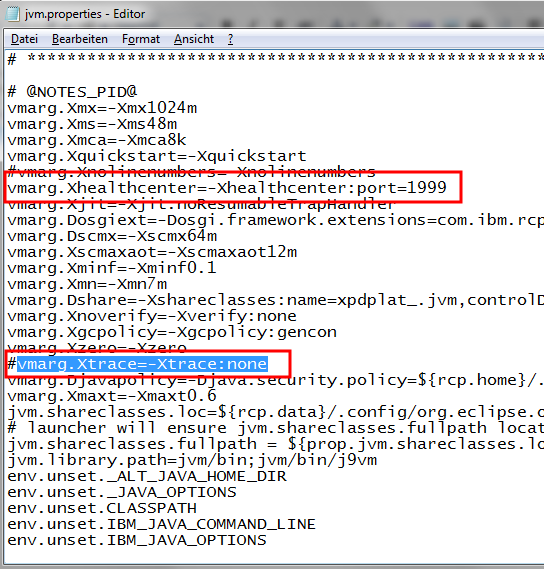
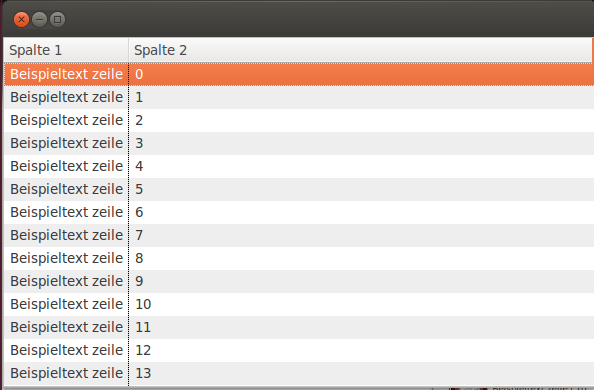
Nachdem der Healthcenteragent in der JVM installiert ist, muss man noch den Aufruf der JVM von Notes anpassen, damit der Agent bei jedem Start von Notes aktiviert wird. Dies erreicht man in dem man die Datei "C:\Program Files (x86)\IBM\Lotus\Notes\framework\rcp\deploy\jvm.properties" editiert. In diese Datei muss erstens der Eintrag "vmarg.Xhealthcenter=-Xhealthcenter:port=1999" ergänzt und die Optimierung "vmarg.Xtrace=-Xtrace:none" ausgeschaltet werden.
Die Datei sollte dann ca. so aussehen:
Die Portnummer 1999 sollte natürlich frei sein. Diese Portnummer wird verwendet, damit sich die Workbench mit der laufenden JVM verbinden kann.
Die Datei speichern und Lotus Notes neu starten.
Sobald Notes neu gestartet ist, kann man in der Workbench das Profiling starten.
IBM Monitoring and Diag... auswählen und auf starten klicken.
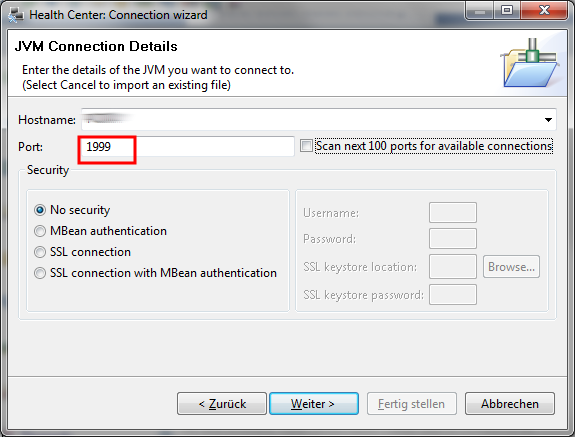
Einmal weiter klicken und dann in dem Verbindungsdialog die Portnummer die man in der jvm.properties verwendet hat angeben.
Den Haken bei Scan next 100 port for available connections kann man rausnehmen, wenn man die Portnummer richtig angegeben hat. Dann auf weiter klicken.
Wenn alles richtig funktioniert hat, dann sollte die Workbench die laufende Notes jvm gefunden haben und man kann den Assistent mit fertigstellen abschließen.
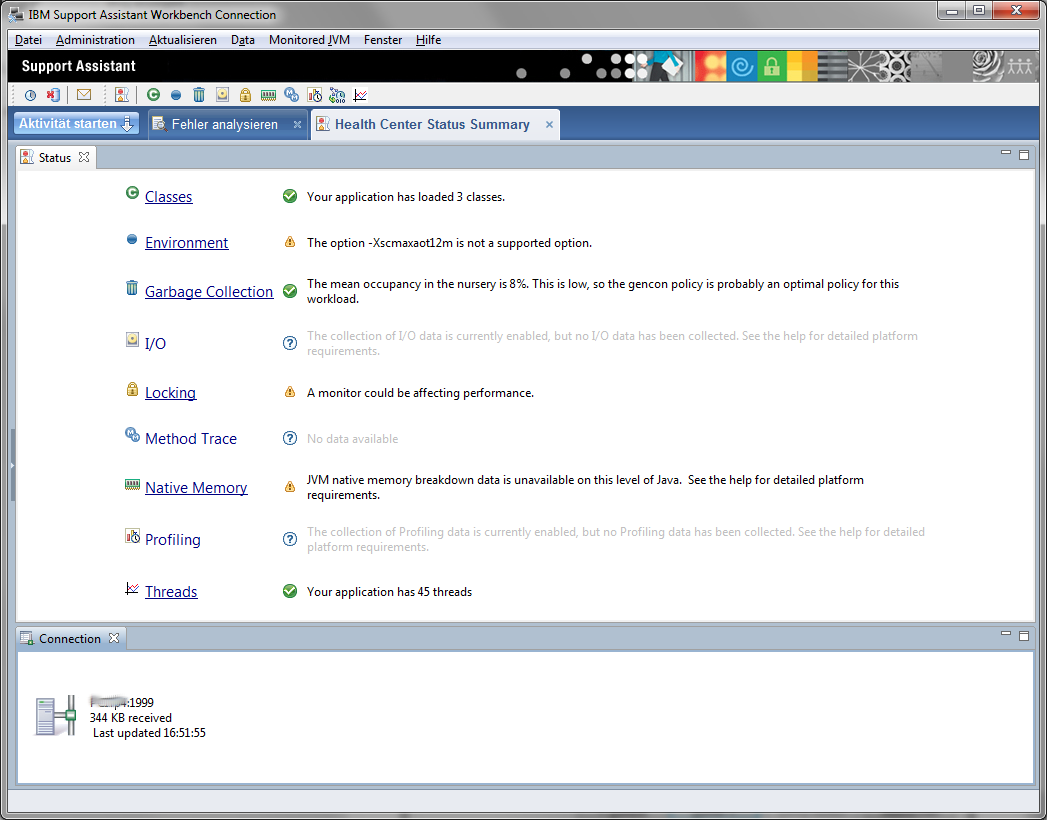
Nach wenigen Sekunden beginnt die Aufzeichnung des Überwachungsvorgang.
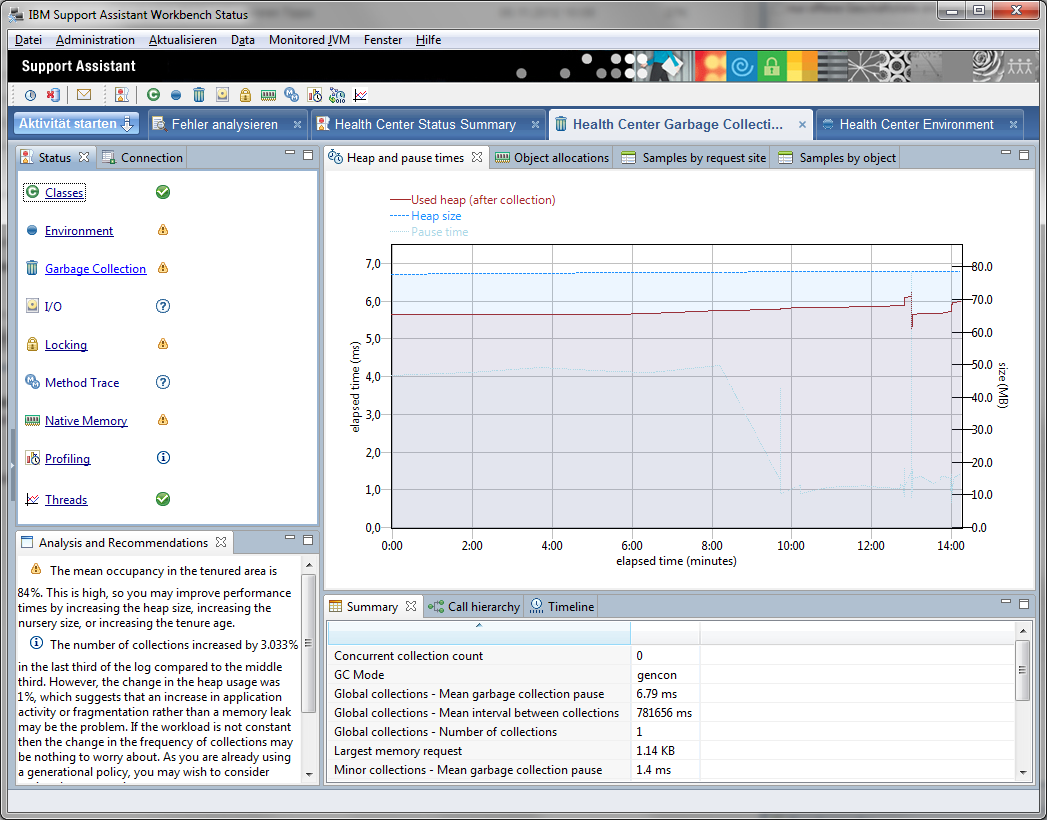
Man kann nun die verschiedenen Bereiche für die schon Daten gesammelt wurden aufrufen. z.B. die Garbagge Collection Ansicht.
Man bekommt auch mehr oder weniger sinnvolle Hinweise, dass etwas nicht richtig konfiguriert ist.
Im dritten Teil der Profiling Serie möchte ich dann zeigen, wie man einzelne Methoden seiner Klassen überwachen kann.
Übrigens falls man sein Programm statt mit der IBM JVM auch mit der Oracle JVM laufen lassen kann, gibt es einen viel einfacheren und meiner Meinung nach auch besseren
Profiler.
P.S. Wenn man nicht gerade die Workbench verwendet, sollte man in der jvm.properties den Healthcenter Eintrag wieder auskommentieren, damit man keinen unnötigen Overhead produziert.