One of the most important components of a server is the Disk subsystem. If you need information's how to optimize or analyze the IO performance of your Power System with IBM i, i recommend to watch the presentation "IBM i Disk Performance" from Satid Singkorapoom.
Abstract: This presentation provides technical performance information on Power Systems' internal disk HW subsystem when managed by IBM i and OS/400. You can learn about how IBM i manages disk allocation for data and memory faulting and what IBM i tools are available for use to monitor important IBM i disk performance parameters to identify if performance issue is impending or not and how to handle the issue. Various good performance guidelines are also provided to help you effectively handle this matter.
Showing posts with label Performance. Show all posts
Showing posts with label Performance. Show all posts
Tuesday, August 26, 2014
Saturday, June 14, 2014
IBM i Performance FAQ updated.
One of the most valuable source for information's about performance on the IBM i is the "IBM i Performance FAQ" got and update in June. This document contains many hints about performance topics and links to other IBM performance resources like:

- What is Performance?
- How to benchmark performance?
- How to size as system?
- Capacity Planning?
- Proactive Performance Monitoring.
- Performance Data Collectors and Analysis Tools.
- Native I/O
- Compiler Optimization
- Java
- Job and Diskwatcher
Monday, November 11, 2013
Neue Version des NRPC Parser auf OpenNTF
Eines meiner wichtigsten Werkzeuge zur Optimierung von Domino Performance Problemen wurde aktualisiert. Die neue Version des NRPC Parser 1.0.12 kann jetzt mit der Angabe der Thread ID in neueren Versionen von Notes umgehen. Eine Beschreibung wie man den NRPC Parser verwenden kann, findet man unter Lösen von Notes Performanceproblemen mit dem NRPC Parser.
Wednesday, September 11, 2013
The latest JDK update includes Java Mission Control as a great new feature
Today Oracle has posted update 40 for Java 1.7 on their Java Downloads site. This update does not only bring bug fixes and security updates, but it brings also a great new feature to analyze performance problems in your java programs called "Oracle Java Mission Control" . This powerful tool was ported from the JRockit to the Hotspot JVM.
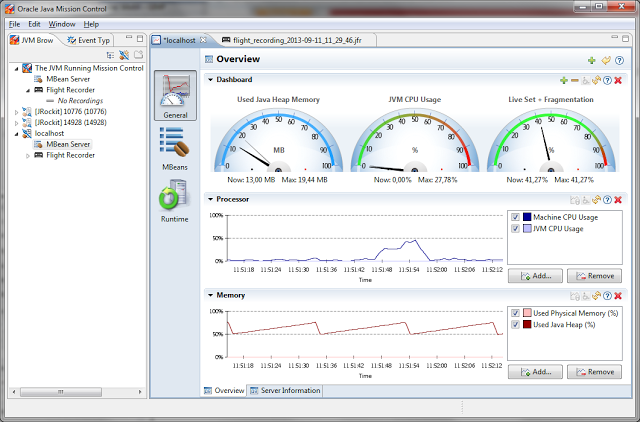
I have run some short tests with "Mission Control" and it looks really very interesting. You will get a deep understanding what is going on in the JVM which runs your code. You will see how long your program execution is stopped by garbage collection or what overhead the compilation of hotspots in your code will add to the execution of your program.
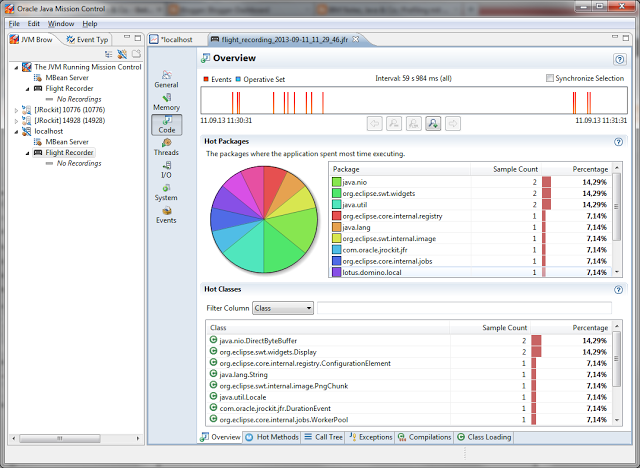
Unfortunately "Java Mission Control" can only connect to Oracles JVM and not to other JVM's like the one from IBM. So if you want to analyze plugins running in Notes you still have to use the "IBM Support Assistance Workbench" which looks a little bit old compared to the new "Oracle Java Mission Control".
A strange thing is, that "Java Mission Control" is based on Eclipse RCP and SWT and not Netbeans RCP and Java FX.
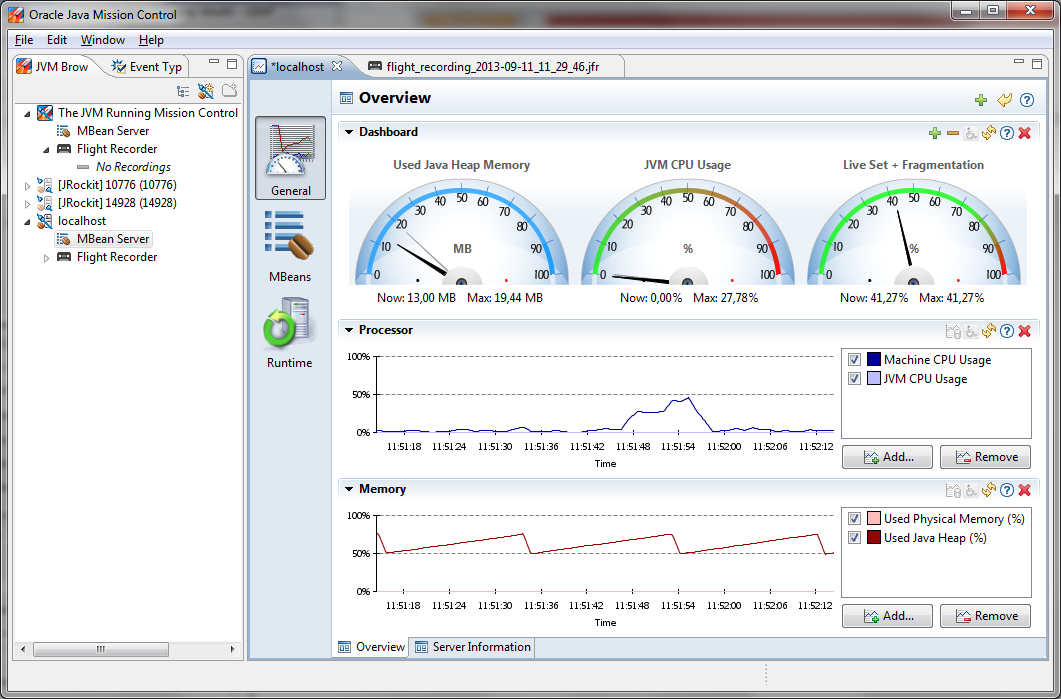
I have run some short tests with "Mission Control" and it looks really very interesting. You will get a deep understanding what is going on in the JVM which runs your code. You will see how long your program execution is stopped by garbage collection or what overhead the compilation of hotspots in your code will add to the execution of your program.
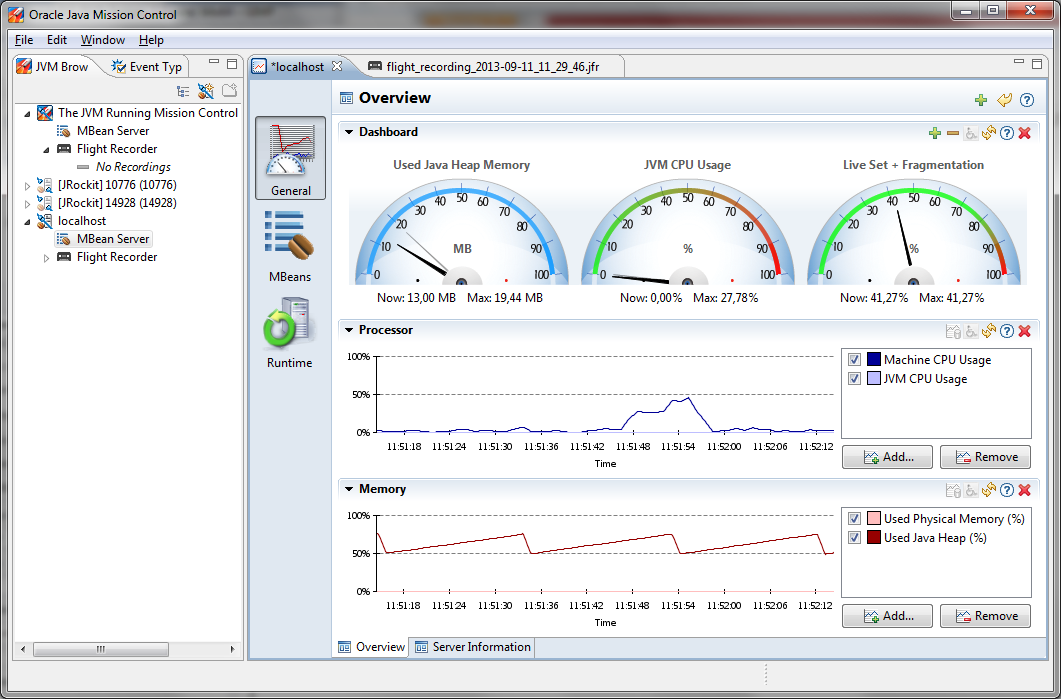{kind=link}
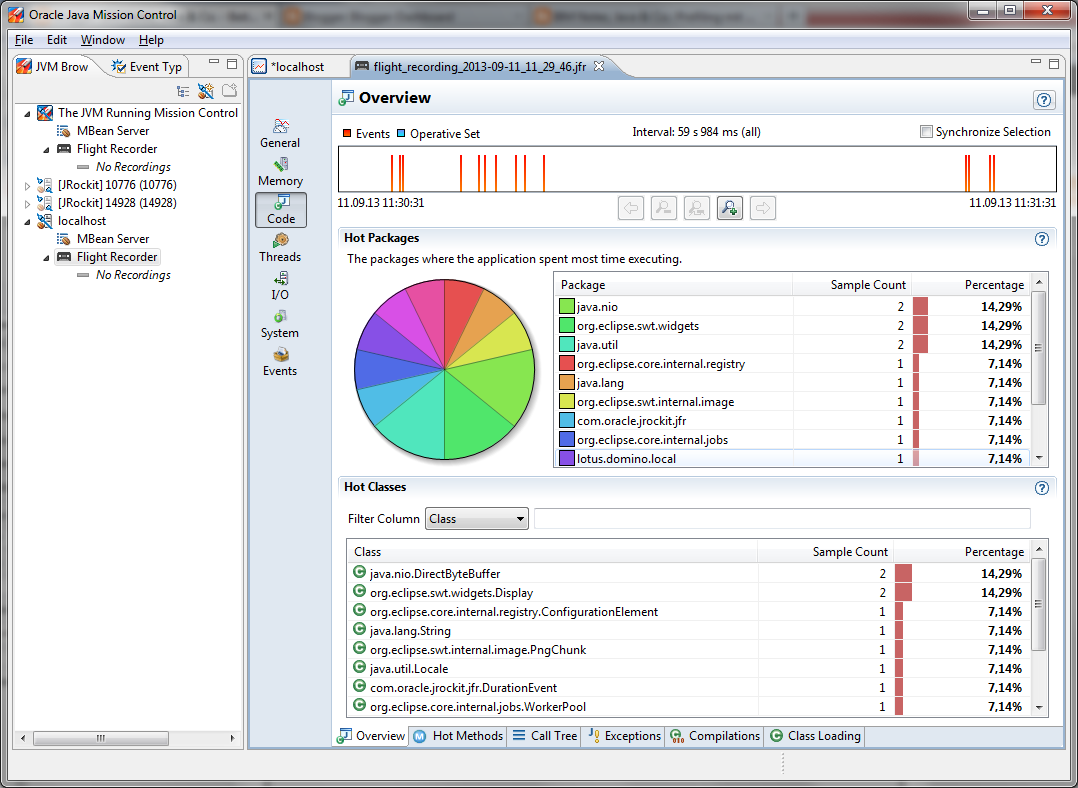
Unfortunately "Java Mission Control" can only connect to Oracles JVM and not to other JVM's like the one from IBM. So if you want to analyze plugins running in Notes you still have to use the "IBM Support Assistance Workbench" which looks a little bit old compared to the new "Oracle Java Mission Control".
A strange thing is, that "Java Mission Control" is based on Eclipse RCP and SWT and not Netbeans RCP and Java FX.
Saturday, April 20, 2013
Improve File enumeration performance in the admin client
Since Domino 8.5 there have been many files in the data/domino directory on the server. So every time you refresh the files tab you have to wait while the server scans the whole data/domino directory. Although some contents like domino/js is not scanned this can take some time. Fortunatly there is a notes.ini setting which disable file scans in the domino directory.
To enable this feature you cann add ADMIN_CLIENT_SKIP_DOMINO=1 to the notes.ini of the server or you can set this value with SET CONFIGURATION ADMIN_CLIENT_SKIP_DOMINO=1 on the console.
I have tried this on my development server. Without ADMIN_CLIENT_SKIP_DOMINO=1 the file enumeration runs 4 seconds and with this setting in the notes.ini of the server the enumeration has finished immediatly after pressing the F9 key.
To enable this feature you cann add ADMIN_CLIENT_SKIP_DOMINO=1 to the notes.ini of the server or you can set this value with SET CONFIGURATION ADMIN_CLIENT_SKIP_DOMINO=1 on the console.
I have tried this on my development server. Without ADMIN_CLIENT_SKIP_DOMINO=1 the file enumeration runs 4 seconds and with this setting in the notes.ini of the server the enumeration has finished immediatly after pressing the F9 key.
Sunday, April 14, 2013
Improve your Domino Server Performance on the System i
On Windows it is pretty clear that Domino Servers only perform well, when the admin regulary defragment the file system where the Domino data is stored. Unfortunatly many System i admins do not know that fragmentation of Domino databases is a problem on their system too. So they do not get the best performance possible and with every year of using the server the problem of framgentation gets bigger and bigger.
The defragmentation of the disks in a System i Server can be done with the command STRDSKRGZ.
So login into your System i with a 5250 Terminal client and execute the STRDSKRGZ command:
The defragmentation of the disks in a System i Server can be done with the command STRDSKRGZ.
So login into your System i with a 5250 Terminal client and execute the STRDSKRGZ command:
Friday, April 12, 2013
The Art of Java performance tuning.
There was a very interesting session at Eclipse Con 2013 in Boston about low level java performance tuning from Ed Merks. You can find the session slides at: http://www.eclipsecon.org/2013/sites/eclipsecon.org.2013/files/JavaPerformanceTuning.pptx
P. S. The interesting slides start at slide 17.
P. S. The interesting slides start at slide 17.
Friday, March 29, 2013
Using contig.exe to analyze and remove fragmentation
The split of files in fragments can have serious impact on the performance of the Notes client or the Domino server. So it is very important to control the framgentation of the installation directory of Notes Domino and the data directories. The on board defrag tool of Windows is often not much help, because it can only defrag the whole harddisk and it cannot generate a report to show which file are fragmented and which are not. But Microsoft provides a tool which can analyze single files, directories or whole directory trees. It is called contig.exe. Contig.exe can be downloaded from http://technet.microsoft.com/en-us/sysinternals/bb897428.aspx.
The download contains one file (contig.exe) which should be extracted to a directory contained in the Windows path for example "c:\windows\system32". To analyze the fragmentation of the notesinstall directory you can use the following command line:
contig -a -v -s "c:\Program Files (x86)\ibm\Notes" > c:\temp\analyze.txt
-a only make an anaylze and do not defrag the files.
-v Verbose
-s Recursive subdirectorys
">c:\temp\anaylze.txt" write the report in the specified file.
The report contains for every file a entry with the count of fragments and a summary at the end:
....
Processing c:\Program Files (x86)\ibm\Notes\nlnotes.exe:
Scanning file...
[Cluster] Runlength
[0] 247
[2140] 150
[3400] 250
File size: 2759272 bytes
c:\Program Files (x86)\ibm\Notes\nlnotes.exe is in 3 fragments
------------------------
Summary:
Number of files processed : 22382
Average fragmentation : 10 frags/file
When you want to really defrag this files then remove the -a option and run the command again.
Contig.exe allows the use of wildcards to select files for defragmentation. So when you want to defrag all your nsf's in the Domino Data directory you can use:
contig -s "c:\Program Files (x86)\ibm\Domino\data\*.nsf"
The download contains one file (contig.exe) which should be extracted to a directory contained in the Windows path for example "c:\windows\system32". To analyze the fragmentation of the notesinstall directory you can use the following command line:
contig -a -v -s "c:\Program Files (x86)\ibm\Notes" > c:\temp\analyze.txt
-a only make an anaylze and do not defrag the files.
-v Verbose
-s Recursive subdirectorys
">c:\temp\anaylze.txt" write the report in the specified file.
The report contains for every file a entry with the count of fragments and a summary at the end:
....
Processing c:\Program Files (x86)\ibm\Notes\nlnotes.exe:
Scanning file...
[Cluster] Runlength
[0] 247
[2140] 150
[3400] 250
File size: 2759272 bytes
c:\Program Files (x86)\ibm\Notes\nlnotes.exe is in 3 fragments
------------------------
Summary:
Number of files processed : 22382
Average fragmentation : 10 frags/file
When you want to really defrag this files then remove the -a option and run the command again.
Contig.exe allows the use of wildcards to select files for defragmentation. So when you want to defrag all your nsf's in the Domino Data directory you can use:
contig -s "c:\Program Files (x86)\ibm\Domino\data\*.nsf"
Tuesday, March 5, 2013
Messen der Netzwerklatenz bei TCP/IP Verbindungen
Bei Client Server Anwendungen wie z.B. Lotus Notes spielt nicht nur die Bandbreite sondern auch die Netzwerklatenz der Verbindung eine große Rolle. Unter Netzwerklatenz versteht man die Zeit die es braucht bis auf eine Anfrage eine Antwort vom Server zurückkommt. Wenn man weiß, dass Lotus Notes beim Öffnen eines Dokuments sämtliche Abfragen, wie DBLookups und ähnliches synchron hintereinander durchführt, spielt es schon eine große Rolle, ob jeder Netzwerkzugriff unter 1 Millisekunde oder eher im 100 Millisekundenbereich dauert. Dazu ein Beispiel: Das Öffnen von einem Notes Dokument benötigt 15 NRPC Aufrufe. Wenn nun die Netzwerklatenz 1 ms beträgt, dann ist der Overhead durch das Netzwerk nur 15 Millisekunden. Wenn man aber über einen WAN Link mit langsamer Latenz (ca. 100 ms) arbeitet, dann ist der Overhead durch die Netzwerklatenz schon 1,5 Sekunden. Damit sollte klar sein, warum Notes ohne lokalen Repliken so bescheiden über WAN Links funktioniert.
Wie kann man nun aber die Netzwerklatenz messen. Eine ganz rudimentäre Möglichkeit bietet der Befehl "PING" den alle Betriebssysteme bereits mitbringen. Aber ping hat den Nachteil, dass es erstens nur kleine ICMP Pakete zum Messen verschickt, die unter Umständen wesentlich besser performen als große Datenpakete wie sie in Anwendungen normalerweise auftreten. Weiters kann es die Latenz nur mit einer Auflösung von 1 ms angeben.
Doch es gibt ein Ping Tool von Microsoft (Sysinternals), dass alle diese Probleme lösen kann.
Nach dem Entpacken des Download kopiert man den "PSPING.EXE" Befehl einmal auf den Client und einmal auf den Server zwischen denen man die Latenz messen will. Danach startet man auf dem Server PSPING im Sever Modus.
psping -s x.x.x.x:y
x.x.x.x ist dabei die Adresse der Netzwerkschnittstelle im Server z.B. 10.0.0.15.
y ist die Portnummer auf der PSPING auf eingehende Anfragen antworten soll.
Natürlich muss man auf dem Server auch noch den gewählten Port auf der Windows Firewall freigeben, oder die Windows Firewall während der Messung deaktivieren.
Auf dem Client kann man dann die Messung mit folgenden Befehl starten.
psping -l 4096 -n 500 -h 20 x.x.x.x:y
Der Befehl sendet 500 4k große Datenpakete an den Server x.x.x.x:y und misst die Latenzzeit. Nach Abschluss der Messung gibt er dann die geringste, die durchschnittliche und die maximale Latenz aus. Weiters erstellt er eine Verteilung der einzelnen Messungen. Die Anzahl der Verteilungen wird über den Paramter -h gesteuert.
Hier ein Beispiel für eine schnelle LAN Verbindung:
TCP latency test connecting to x.x.x.x:y: Connected
505 iterations (warmup 5) sending 4096 bytes latency test: 100%
TCP roundtrip latency statistics (post warmup):
Sent = 500, Size = 4096, Total Bytes: 2048000,
Minimum = 0.26ms, Maxiumum = 7.41ms, Average = 0.34ms
Latency Count
0.26 496
0.63 2
1.01 0
1.39 1
1.76 0
2.14 0
2.51 0
2.89 0
3.27 0
3.64 0
4.02 0
4.40 0
4.77 0
5.15 0
5.52 0
5.90 0
6.28 0
6.65 0
7.03 1
7.41 0
und das selbe über ein WAN Link:
TCP latency test connecting to x.x.x.x:y: Connected
505 iterations (warmup 5) sending 4096 bytes latency test: 100%
TCP roundtrip latency statistics (post warmup):
Sent = 500, Size = 4096, Total Bytes: 2048000,
Minimum = 42.39ms, Maxiumum = 445.09ms, Average = 50.24ms
Latency Count
42.39 457
63.59 37
84.78 2
105.98 0
127.17 0
148.36 0
169.56 0
190.75 0
211.95 0
233.14 0
254.34 0
275.53 0
296.73 2
317.92 0
339.12 0
360.31 0
381.51 0
402.70 1
423.90 1
445.09 0
Vor allem wenn man bei seinem WAN Link sehr viele Ausreißer nach oben hat, sollte man unbedingt an seinem Netzwerk arbeiten. z.B. Quality of Service einführen. Nach den Tuningmassnahmen kann man dann wieder bequem mit PSPING prüfen, ob die Massnahmen auch etwas gebracht haben.
Wie kann man nun aber die Netzwerklatenz messen. Eine ganz rudimentäre Möglichkeit bietet der Befehl "PING" den alle Betriebssysteme bereits mitbringen. Aber ping hat den Nachteil, dass es erstens nur kleine ICMP Pakete zum Messen verschickt, die unter Umständen wesentlich besser performen als große Datenpakete wie sie in Anwendungen normalerweise auftreten. Weiters kann es die Latenz nur mit einer Auflösung von 1 ms angeben.
Doch es gibt ein Ping Tool von Microsoft (Sysinternals), dass alle diese Probleme lösen kann.
Nach dem Entpacken des Download kopiert man den "PSPING.EXE" Befehl einmal auf den Client und einmal auf den Server zwischen denen man die Latenz messen will. Danach startet man auf dem Server PSPING im Sever Modus.
psping -s x.x.x.x:y
x.x.x.x ist dabei die Adresse der Netzwerkschnittstelle im Server z.B. 10.0.0.15.
y ist die Portnummer auf der PSPING auf eingehende Anfragen antworten soll.
Natürlich muss man auf dem Server auch noch den gewählten Port auf der Windows Firewall freigeben, oder die Windows Firewall während der Messung deaktivieren.
Auf dem Client kann man dann die Messung mit folgenden Befehl starten.
psping -l 4096 -n 500 -h 20 x.x.x.x:y
Der Befehl sendet 500 4k große Datenpakete an den Server x.x.x.x:y und misst die Latenzzeit. Nach Abschluss der Messung gibt er dann die geringste, die durchschnittliche und die maximale Latenz aus. Weiters erstellt er eine Verteilung der einzelnen Messungen. Die Anzahl der Verteilungen wird über den Paramter -h gesteuert.
Hier ein Beispiel für eine schnelle LAN Verbindung:
TCP latency test connecting to x.x.x.x:y: Connected
505 iterations (warmup 5) sending 4096 bytes latency test: 100%
TCP roundtrip latency statistics (post warmup):
Sent = 500, Size = 4096, Total Bytes: 2048000,
Minimum = 0.26ms, Maxiumum = 7.41ms, Average = 0.34ms
Latency Count
0.26 496
0.63 2
1.01 0
1.39 1
1.76 0
2.14 0
2.51 0
2.89 0
3.27 0
3.64 0
4.02 0
4.40 0
4.77 0
5.15 0
5.52 0
5.90 0
6.28 0
6.65 0
7.03 1
7.41 0
und das selbe über ein WAN Link:
TCP latency test connecting to x.x.x.x:y: Connected
505 iterations (warmup 5) sending 4096 bytes latency test: 100%
TCP roundtrip latency statistics (post warmup):
Sent = 500, Size = 4096, Total Bytes: 2048000,
Minimum = 42.39ms, Maxiumum = 445.09ms, Average = 50.24ms
Latency Count
42.39 457
63.59 37
84.78 2
105.98 0
127.17 0
148.36 0
169.56 0
190.75 0
211.95 0
233.14 0
254.34 0
275.53 0
296.73 2
317.92 0
339.12 0
360.31 0
381.51 0
402.70 1
423.90 1
445.09 0
Vor allem wenn man bei seinem WAN Link sehr viele Ausreißer nach oben hat, sollte man unbedingt an seinem Netzwerk arbeiten. z.B. Quality of Service einführen. Nach den Tuningmassnahmen kann man dann wieder bequem mit PSPING prüfen, ob die Massnahmen auch etwas gebracht haben.
Thursday, February 28, 2013
Performance bei der String Konkatenierung in Java
Ein immer wieder gern gemachter Fehler der zu schlechter Performance in Java Programmen führt ist, das Zusammenbauen von Strings mit dem "+" Operator. Vor allem wenn dieses in einer Schleife gemacht wird steigt der Speicherverbrauch enorm an und der Garbagge Collector läuft Amok. Ein kleines Beispiel. Wir haben eine Liste (List<Person>) mit 100 Namen und wollen diese in eine CSV Datei ausgeben. Folgender Code erledigt die Aufgabe zwar völlig richtig. Wenn man das Programm aber in einem Profiler laufen lässt sieht man, dass jede Menge Hauptspeicher verschwendet wird und das Programm die meiste Zeit mit Garbagge Collecting verbringt.
Warum ist das so? Die Erklärung liegt darin, dass ein String in Java unveränderbar ist. Das heißt es ist in Java nicht möglich, dass man einen String einfach zu einem anderen hinzufügt. Viel mehr wird bei jeder Konkatenierung ein neuer String erzeugt. Mit diesem Hintergrund sieht man sofort, dass in unserem Programm jede Menge sinnloser Strings erzeugt werden, die sofort wieder von der Garbagge Collection entsorgt werden müssen. Vor allem böse ist aber die "result=result+..." Anweisung. Den der result String wird mit jedem Schleifendurchlauf länger und länger und dadurch wird auch der Hauptspeicher der bei jedem Schleifendurchlauf für den String angefordert werden muß größer und größer. Bei 100 Namen wird das vielleicht noch nicht so viel ausmachen. Bei 1000 Namen kommen da aber gleich mal viele Garbagge Collection Zyklen zusammen und schon haben wir wieder ein Programm, dass die urban legend das Java langsam ist scheinbar bestätigt.
Doch natürlich besitzt die Javaklassenbibliothek mit der StringBuilder Klasse eine Lösung für das Problem. Mit dieser veränderlichen Klasse können fast beliebig lange Strings einfach und effizient zusammengebaut werden.
Mit dieser Variante haben wir die Anzahl der unnötig erstellen String Objekte dramatisch reduziert. Intern verwendet der StringBuilder ein char Array, dass immer wieder vergrössert wird. Das char Array ist standardmäßig mit 16 Zeichen intialisiert und bei jeder Erweiterung wird die Kapazität verdoppelt. Das ist in unserem Beispiel natürlich immer noch eine Verschwendung. Deshalb empfiehlt es sich den StringBuilder als Parameter eine Schätzung der maximalen Größe des StringBuilder mitzugeben. Dadurch kann man nocheinmal einen Performancegewinn erzielen.
Falls das Zusammensetzen des Strings aus mehreren Threads erfolgen soll, sollte man statt des StringBuilders die Klasse StringBuffer verwenden. Letztere ist nämlich im Gegensatz zu StringBuilder Threadsafe.
String result = "\"Vorname\",\"Nachname\"\n";
for (Person person : personen) {
result = result + "\"" + person.getVorname() + "\",\"" + person.getNachname() + "\n";
}
System.out.println(result);
Warum ist das so? Die Erklärung liegt darin, dass ein String in Java unveränderbar ist. Das heißt es ist in Java nicht möglich, dass man einen String einfach zu einem anderen hinzufügt. Viel mehr wird bei jeder Konkatenierung ein neuer String erzeugt. Mit diesem Hintergrund sieht man sofort, dass in unserem Programm jede Menge sinnloser Strings erzeugt werden, die sofort wieder von der Garbagge Collection entsorgt werden müssen. Vor allem böse ist aber die "result=result+..." Anweisung. Den der result String wird mit jedem Schleifendurchlauf länger und länger und dadurch wird auch der Hauptspeicher der bei jedem Schleifendurchlauf für den String angefordert werden muß größer und größer. Bei 100 Namen wird das vielleicht noch nicht so viel ausmachen. Bei 1000 Namen kommen da aber gleich mal viele Garbagge Collection Zyklen zusammen und schon haben wir wieder ein Programm, dass die urban legend das Java langsam ist scheinbar bestätigt.
Doch natürlich besitzt die Javaklassenbibliothek mit der StringBuilder Klasse eine Lösung für das Problem. Mit dieser veränderlichen Klasse können fast beliebig lange Strings einfach und effizient zusammengebaut werden.
StringBuilder result = new StringBuilder();
result.append("\"Vorname\",\"Nachname\"\n");
for (Person person : personen) {
result.append("\"");
result.append(person.getVorname());
result.append("\",\"");
result.append(person.getNachname());
result.append("\n");
}
System.out.println(result.toString());
Mit dieser Variante haben wir die Anzahl der unnötig erstellen String Objekte dramatisch reduziert. Intern verwendet der StringBuilder ein char Array, dass immer wieder vergrössert wird. Das char Array ist standardmäßig mit 16 Zeichen intialisiert und bei jeder Erweiterung wird die Kapazität verdoppelt. Das ist in unserem Beispiel natürlich immer noch eine Verschwendung. Deshalb empfiehlt es sich den StringBuilder als Parameter eine Schätzung der maximalen Größe des StringBuilder mitzugeben. Dadurch kann man nocheinmal einen Performancegewinn erzielen.
Falls das Zusammensetzen des Strings aus mehreren Threads erfolgen soll, sollte man statt des StringBuilders die Klasse StringBuffer verwenden. Letztere ist nämlich im Gegensatz zu StringBuilder Threadsafe.
Monday, February 4, 2013
Lösen von Notes Performanceproblemen mit dem NRPC Parser
Der Notes Client besitzt eine eingebaute Tracefunktion um die NRPC (Notes Remote Procedure Call) Kommunikation zwischen einem Client und dem Server zu tracen. Leider ist das Log, dass diese Tracefunktionalität zur Verfügung stellt, etwas unübersichtlich und kryptisch. Jedoch gibt es auf OpenNTF eine Datenbank mit der man die Analyse vereinfachen kann.
Hier die Schritte um eine Performanceanalyse mit der Datenbank durchzuführen:
Downloaden Sie den NRPC Parser von OpenNTF und signieren Sie die Datenbank mit einer Developer id, damit Sie keine Probleme mit der ECL haben.
Öffnen Sie die Parserdatenbank und klicken Sie auf die
 Schaltfläche. Damit werden in Ihrer notes.ini die Einträge
Schaltfläche. Damit werden in Ihrer notes.ini die Einträge
Jetzt muss der Notesclient neu gestart werden und man kann die Funktion in Notes durchführen mit der man ein Performanceproblem hat. z.B. eine Datenbank öffnen, oder ein Dokument aufmachen.
Danach sollte man die Notes.ini Einträge mit
 wieder deaktivieren und den Notesclient neu starten.
wieder deaktivieren und den Notesclient neu starten.
Danach kann man mit der Schaltfläche
 die erstellte Datei analysieren lassen und bekommt dann für jeden Aufruf einer Funktion auf dem Server eine Zeile in der genau steht was gemacht wurde, wie lange dieser Aufruf gedauert hat und wieviele Daten vom Server gesendet und empfangen wurden.
die erstellte Datei analysieren lassen und bekommt dann für jeden Aufruf einer Funktion auf dem Server eine Zeile in der genau steht was gemacht wurde, wie lange dieser Aufruf gedauert hat und wieviele Daten vom Server gesendet und empfangen wurden.
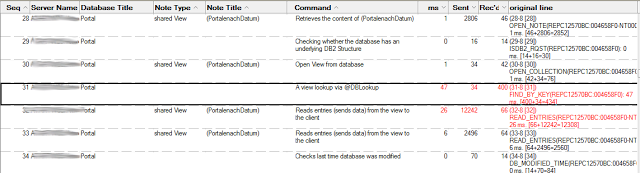
Aufwendige Operationen sind rot markiert. Die Spalte Sent gibt die Datenmenge in Bytes an die der Server gesendet hat. Die Spalte Rec'd gibt an, wieviel Daten der Server vom Client empfangen hat.
Update 11.11.2013 Wie in den Kommentaren angeführt hat Andrew Magerman eine neue Version des NRPC Parser veröffentlicht, die jetzt auch mit aktuellen Version von Notes korrekt funktioniert. Die Angabe von Debug_ThreadID=0 die man in älteren Versionen des NRPC Parsers benötigte ist daher nicht mehr notwendig. Vielen Dank für dieses Update und das fantastische Tool.
Hier die Schritte um eine Performanceanalyse mit der Datenbank durchzuführen:
Downloaden Sie den NRPC Parser von OpenNTF und signieren Sie die Datenbank mit einer Developer id, damit Sie keine Probleme mit der ECL haben.
Öffnen Sie die Parserdatenbank und klicken Sie auf die
- Client_Clock=1
- Debug_Console=1
- Debug_Outfile=c:\Program Files (x86)\IBM\Lotus\Notes\Data\RPC.txt
- CONSOLE_LOG_ENABLED=1
Jetzt muss der Notesclient neu gestart werden und man kann die Funktion in Notes durchführen mit der man ein Performanceproblem hat. z.B. eine Datenbank öffnen, oder ein Dokument aufmachen.
Danach sollte man die Notes.ini Einträge mit
Danach kann man mit der Schaltfläche
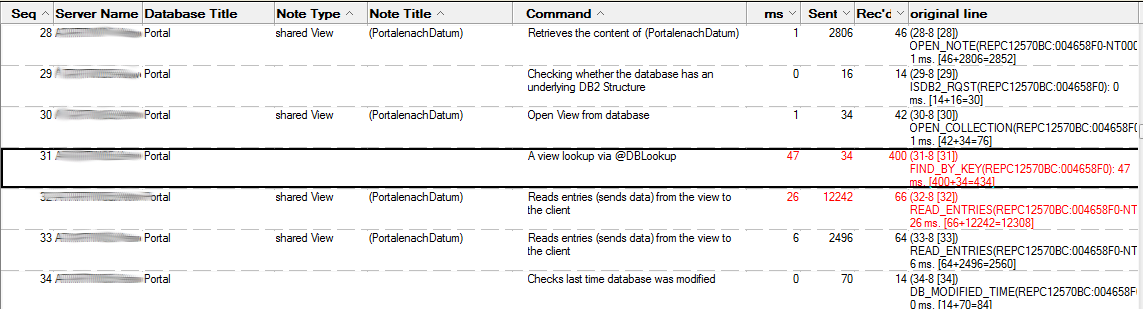
Aufwendige Operationen sind rot markiert. Die Spalte Sent gibt die Datenmenge in Bytes an die der Server gesendet hat. Die Spalte Rec'd gibt an, wieviel Daten der Server vom Client empfangen hat.
Update 11.11.2013 Wie in den Kommentaren angeführt hat Andrew Magerman eine neue Version des NRPC Parser veröffentlicht, die jetzt auch mit aktuellen Version von Notes korrekt funktioniert. Die Angabe von Debug_ThreadID=0 die man in älteren Versionen des NRPC Parsers benötigte ist daher nicht mehr notwendig. Vielen Dank für dieses Update und das fantastische Tool.
Tuesday, November 27, 2012
Fork/Join Framework in Java 7
Auf Heise Developer wurde ein sehr interessanter Artikel über das mit Java 7 eingeführte Fork/Join Framework gepostet. Das Fork/Join Framework sieht sehr interessant aus, um komplexe Aufgaben in kleinere Tasks aufzuteilen und auf mehreren Prozessorcores gleichzeitig auszuführen. Leider wird Java 7 von Notes noch nicht unterstützt. Aber vielleicht ändert sich das ja mit Lotus Notes Social Edition.
Thursday, November 8, 2012
Profiling mit der IBM JVM von Lotus Notes (Teil 2)
Nachdem wir im ersten Teil die IBM Support Assistant Workbench installiert haben, wollen wir uns diesmal ansehen wie man den Healthcenteragent in die JVM von Notes installiert und welche Einstellungen man anpassen muss, damit das Profiling funktioniert.
Als erstes muss man den Healthcenteragent aus der Workbench extrahieren. Man ruft dazu das Hilfecenter auf.
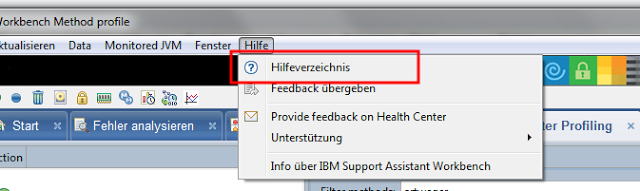
In diesem wählt man in der linken Seitenleiste zuerst den Eintrag "Tool: IBM Monitoring and Diag..." dann den Punkt "Monitoring a running..." und dann "Installing the Health.." Auf der rechten Seite wird dann eine Liste mit den Agents angezeigt. Für Lotus Notes unter Windows sollte man den "Windows x86 32 bit" auswählen.
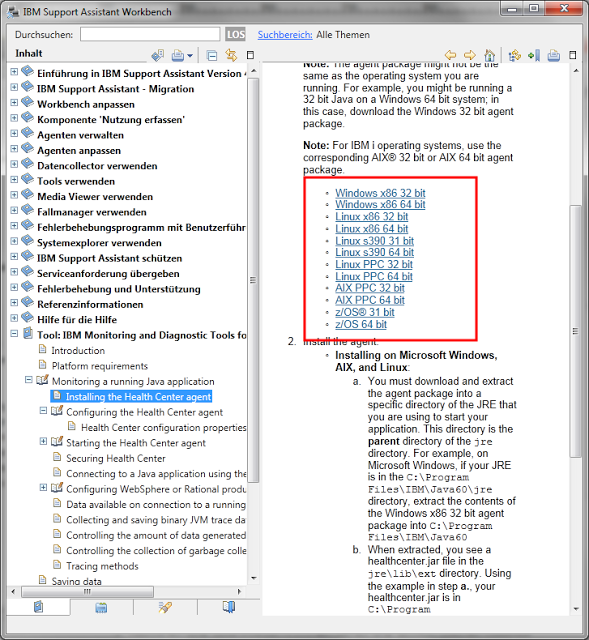
Nach dem Anwählen des Agent erhält man ein Zip File, dass man entpacken muss. In dem Zipfile befindet sich ein Ordner "jre". Den Inhalt dieses Ordners muss man in das jvm Verzeichnis von Notes einkopieren. Unter Windows befindet sich dieses standardmäßig in "C:\Program Files (x86)\IBM\Lotus\Notes\jvm". Eventuell ist schon eine ältere Version des Healtcenteragent installiert. Diese kann problemlos überschrieben werden. Falls man mit eingeschränkten Rechten arbeitet, muss man eventuell noch das Administratorpasswort eingeben. Wichtig ist, dass der Inhalt des jre Verzeichnis aus dem zip wirklich genau in die Verzeichnisstruktur der jvm passt.
Nachdem der Healthcenteragent in der JVM installiert ist, muss man noch den Aufruf der JVM von Notes anpassen, damit der Agent bei jedem Start von Notes aktiviert wird. Dies erreicht man in dem man die Datei "C:\Program Files (x86)\IBM\Lotus\Notes\framework\rcp\deploy\jvm.properties" editiert. In diese Datei muss erstens der Eintrag "vmarg.Xhealthcenter=-Xhealthcenter:port=1999" ergänzt und die Optimierung "vmarg.Xtrace=-Xtrace:none" ausgeschaltet werden.
Die Datei sollte dann ca. so aussehen:
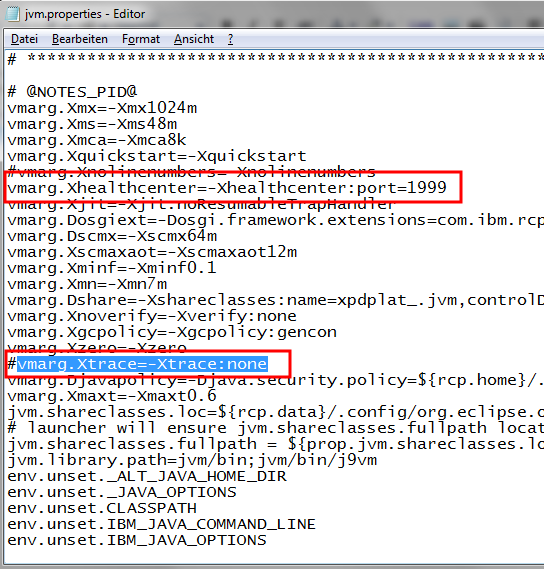
Die Portnummer 1999 sollte natürlich frei sein. Diese Portnummer wird verwendet, damit sich die Workbench mit der laufenden JVM verbinden kann.
Die Datei speichern und Lotus Notes neu starten.
Sobald Notes neu gestartet ist, kann man in der Workbench das Profiling starten.
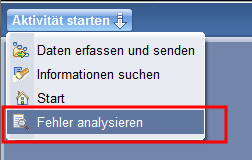
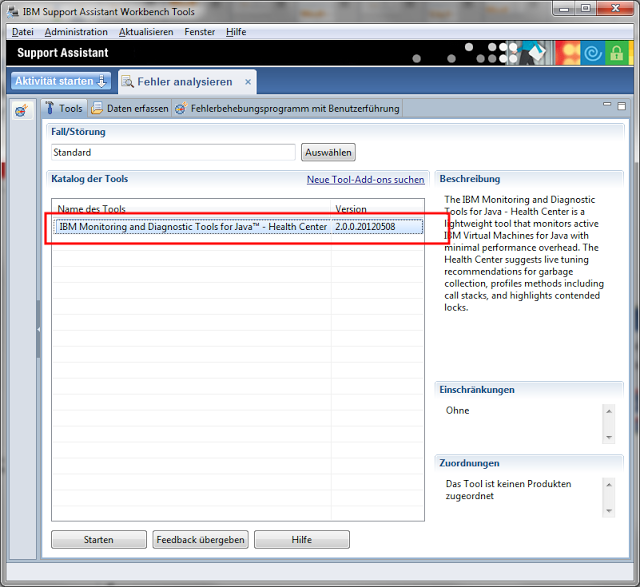
Einmal weiter klicken und dann in dem Verbindungsdialog die Portnummer die man in der jvm.properties verwendet hat angeben.
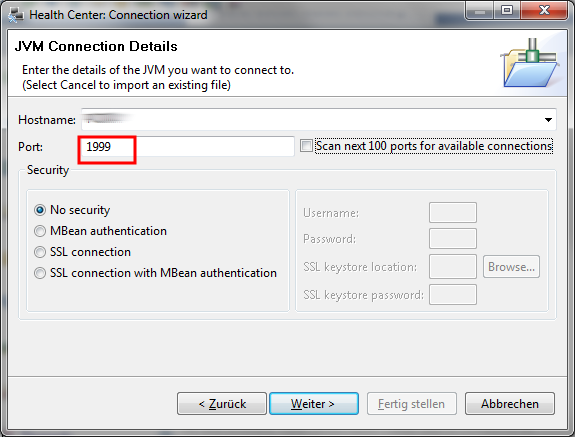
Den Haken bei Scan next 100 port for available connections kann man rausnehmen, wenn man die Portnummer richtig angegeben hat. Dann auf weiter klicken.
Wenn alles richtig funktioniert hat, dann sollte die Workbench die laufende Notes jvm gefunden haben und man kann den Assistent mit fertigstellen abschließen.
Nach wenigen Sekunden beginnt die Aufzeichnung des Überwachungsvorgang.
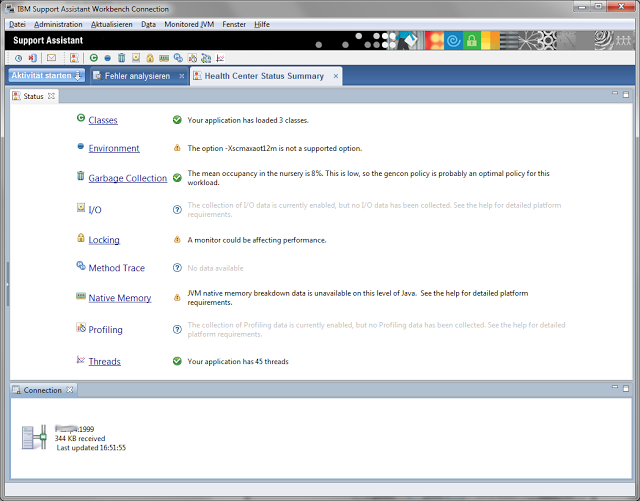
Man kann nun die verschiedenen Bereiche für die schon Daten gesammelt wurden aufrufen. z.B. die Garbagge Collection Ansicht.
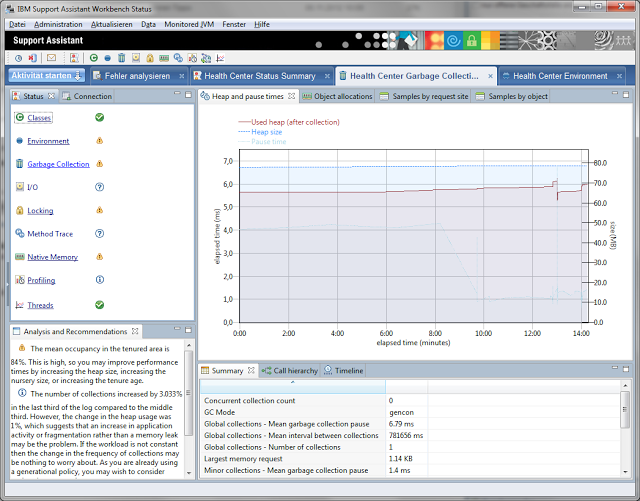
Man bekommt auch mehr oder weniger sinnvolle Hinweise, dass etwas nicht richtig konfiguriert ist.
Im dritten Teil der Profiling Serie möchte ich dann zeigen, wie man einzelne Methoden seiner Klassen überwachen kann.
Übrigens falls man sein Programm statt mit der IBM JVM auch mit der Oracle JVM laufen lassen kann, gibt es einen viel einfacheren und meiner Meinung nach auch besseren Profiler.
P.S. Wenn man nicht gerade die Workbench verwendet, sollte man in der jvm.properties den Healthcenter Eintrag wieder auskommentieren, damit man keinen unnötigen Overhead produziert.
Als erstes muss man den Healthcenteragent aus der Workbench extrahieren. Man ruft dazu das Hilfecenter auf.
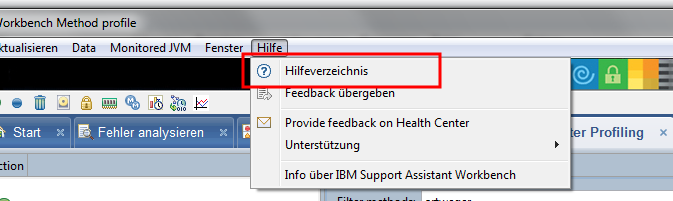
In diesem wählt man in der linken Seitenleiste zuerst den Eintrag "Tool: IBM Monitoring and Diag..." dann den Punkt "Monitoring a running..." und dann "Installing the Health.." Auf der rechten Seite wird dann eine Liste mit den Agents angezeigt. Für Lotus Notes unter Windows sollte man den "Windows x86 32 bit" auswählen.
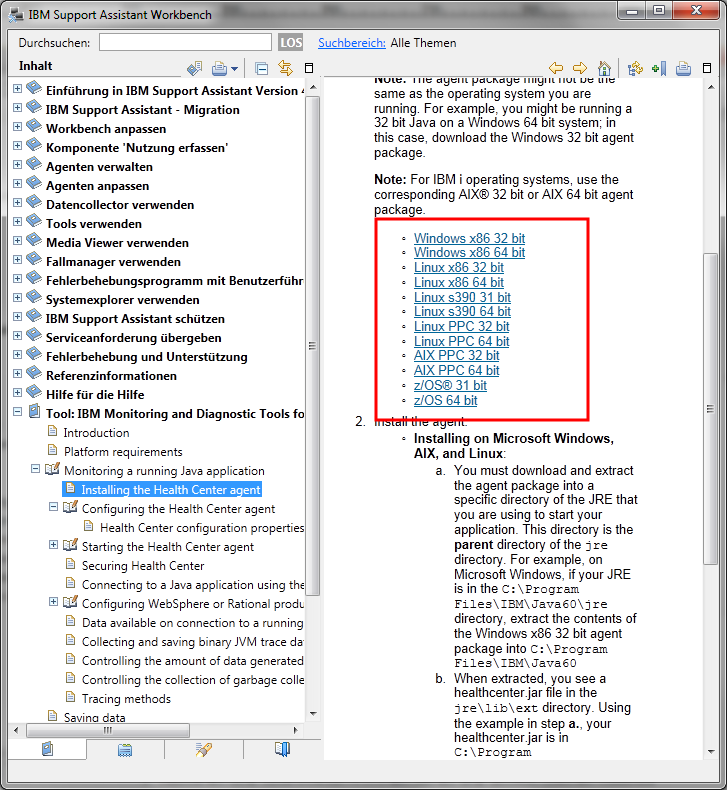
Nach dem Anwählen des Agent erhält man ein Zip File, dass man entpacken muss. In dem Zipfile befindet sich ein Ordner "jre". Den Inhalt dieses Ordners muss man in das jvm Verzeichnis von Notes einkopieren. Unter Windows befindet sich dieses standardmäßig in "C:\Program Files (x86)\IBM\Lotus\Notes\jvm". Eventuell ist schon eine ältere Version des Healtcenteragent installiert. Diese kann problemlos überschrieben werden. Falls man mit eingeschränkten Rechten arbeitet, muss man eventuell noch das Administratorpasswort eingeben. Wichtig ist, dass der Inhalt des jre Verzeichnis aus dem zip wirklich genau in die Verzeichnisstruktur der jvm passt.
Nachdem der Healthcenteragent in der JVM installiert ist, muss man noch den Aufruf der JVM von Notes anpassen, damit der Agent bei jedem Start von Notes aktiviert wird. Dies erreicht man in dem man die Datei "C:\Program Files (x86)\IBM\Lotus\Notes\framework\rcp\deploy\jvm.properties" editiert. In diese Datei muss erstens der Eintrag "vmarg.Xhealthcenter=-Xhealthcenter:port=1999" ergänzt und die Optimierung "vmarg.Xtrace=-Xtrace:none" ausgeschaltet werden.
Die Datei sollte dann ca. so aussehen:
Die Portnummer 1999 sollte natürlich frei sein. Diese Portnummer wird verwendet, damit sich die Workbench mit der laufenden JVM verbinden kann.
Die Datei speichern und Lotus Notes neu starten.
Sobald Notes neu gestartet ist, kann man in der Workbench das Profiling starten.
IBM Monitoring and Diag... auswählen und auf starten klicken.
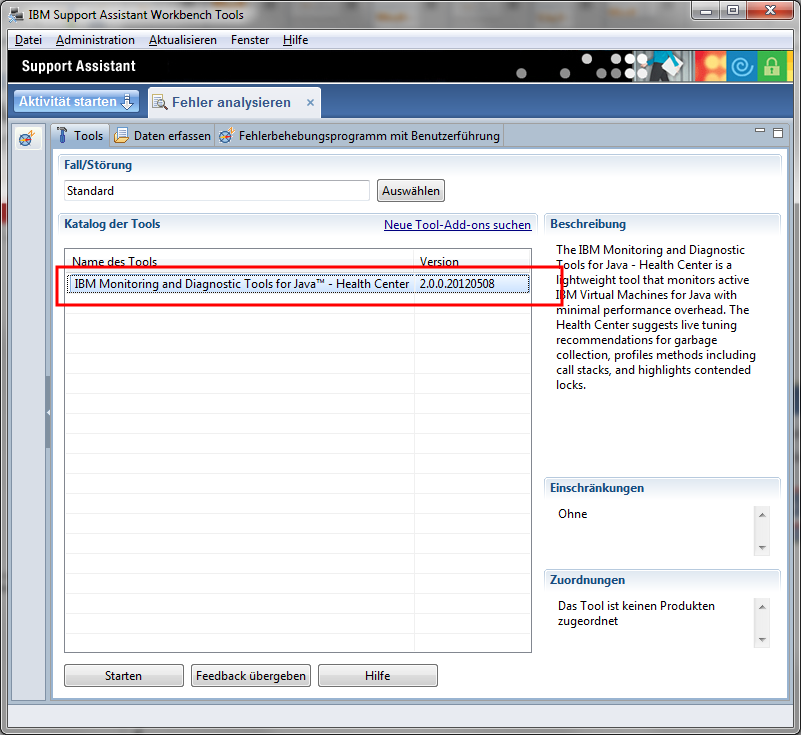
Einmal weiter klicken und dann in dem Verbindungsdialog die Portnummer die man in der jvm.properties verwendet hat angeben.
Den Haken bei Scan next 100 port for available connections kann man rausnehmen, wenn man die Portnummer richtig angegeben hat. Dann auf weiter klicken.
Wenn alles richtig funktioniert hat, dann sollte die Workbench die laufende Notes jvm gefunden haben und man kann den Assistent mit fertigstellen abschließen.
Nach wenigen Sekunden beginnt die Aufzeichnung des Überwachungsvorgang.
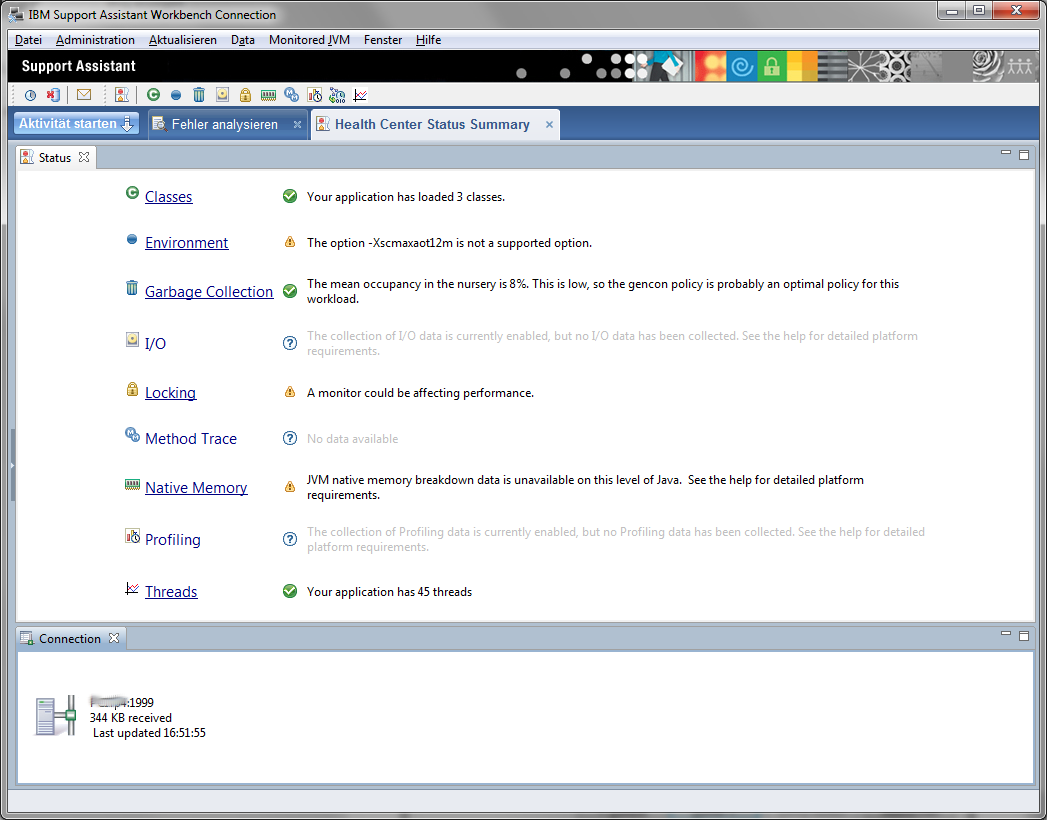
Man kann nun die verschiedenen Bereiche für die schon Daten gesammelt wurden aufrufen. z.B. die Garbagge Collection Ansicht.
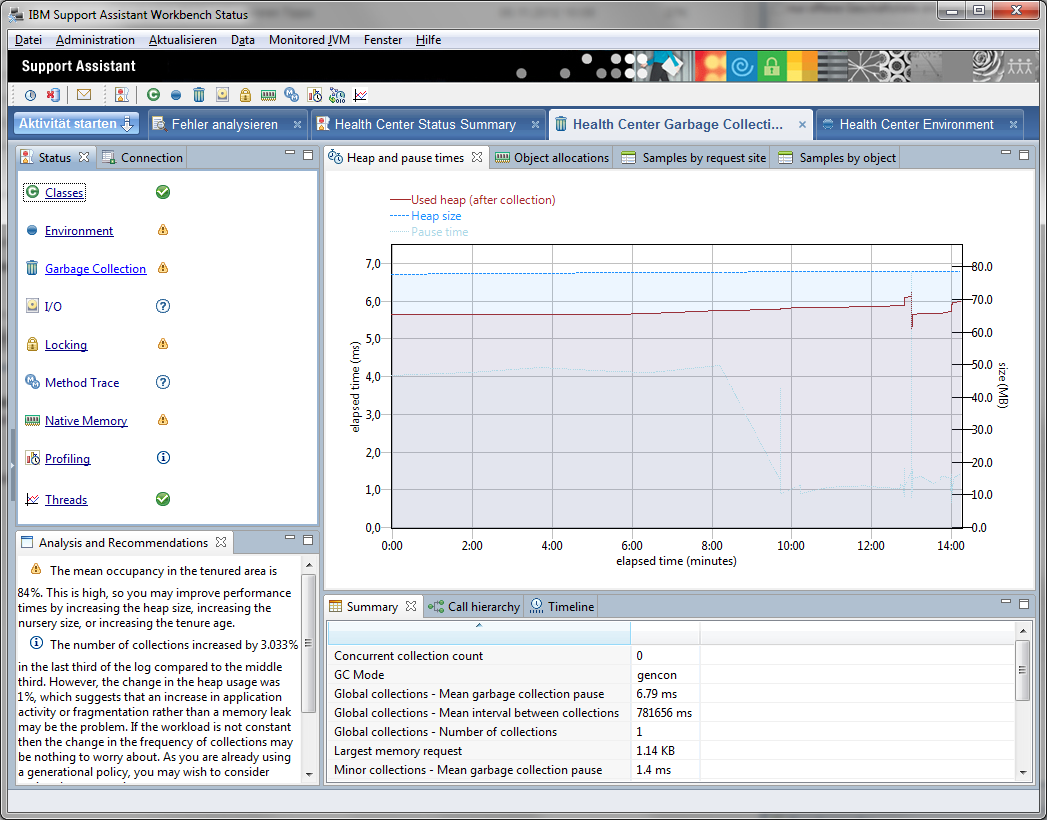
Man bekommt auch mehr oder weniger sinnvolle Hinweise, dass etwas nicht richtig konfiguriert ist.
Im dritten Teil der Profiling Serie möchte ich dann zeigen, wie man einzelne Methoden seiner Klassen überwachen kann.
Übrigens falls man sein Programm statt mit der IBM JVM auch mit der Oracle JVM laufen lassen kann, gibt es einen viel einfacheren und meiner Meinung nach auch besseren Profiler.
P.S. Wenn man nicht gerade die Workbench verwendet, sollte man in der jvm.properties den Healthcenter Eintrag wieder auskommentieren, damit man keinen unnötigen Overhead produziert.
Wednesday, November 7, 2012
Profiling mit der IBM JVM von Lotus Notes (Teil 1)
Für die JVM von Oracle gibt es einen gratis Profiler der sehr gut funktioniert und auch sehr einfach einzusetzen ist. Leider kann dieser Profiler nicht mit der IBM JVM die z.B. in Lotus Notes genutzt wird, verwendet werden. Auch die IBM bietet einen Profiler an, der aber leider ziemlich aufwendig zu installieren ist.
Der erste Schritt ist, dass man falls man die IBM Support Assistance Workbench noch nicht hat, diese unter http://www-01.ibm.com/software/support/isa/ herunterlädt.
Der Inhalt der heruntergeladenen Datei muß nun in einen temporären Ordner entpackt werden.
Der temporäre Ordner sollte auf der gleichen Platte wie das Installationsziel sein, da sonst der Installer während der Installation abstürzt.
Im entpackten Ordner muß man dann die Datei "setupwin32.exe aufrufen.
Die Eula abnicken und solange weiter klicken, bis das Programm fertig installiert ist.
Danach sollte man wenn man mit einem Benutzer arbeitet, der auf das Programmverzeichnis keine Schreibrechte hat für die Workbench ausnahmsweise Schreibrechte vergeben. Der Updater der beim Starten der Anwendung läuft ist nicht schlau genug, dass er über die UAC höhere Rechte anfordert.
Jetzt kann man die Support Assistant Workbench starten. Den Anfangsassistenten kann man falls man nicht einen Proxy einstellen muß beherzt duchklicken. Es dauert dann etwas bis die Workbench sich aus der Updatesite im Internet die richtigen Updates gezogen hat.
Dann die Updates die er anbietet installieren, man braucht jedoch keine Produkt Addons installieren. Diese Seite einfach abbrechen.
Nach einiger Zeit sollte man dann die Meldung bekommen, dass die Workbench erfolgreich upgedated wurde.
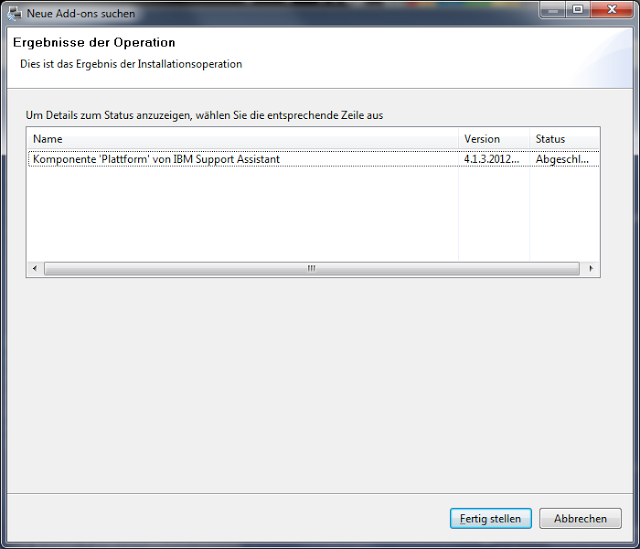
Nach dem Fertigstellung muss man dann noch einmal neustarten.
Jetzt kann man die JVM Healthcentertools in die Support Workbench installieren. Dazu muss man im Menü "Aktualisieren->Neue suchen..." den Punkte "Tool-Add-ons" aufrufen.
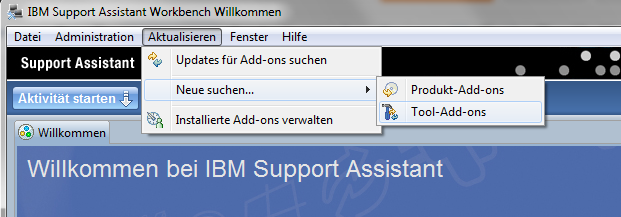
Nach einiger Nachdenkpause der Workbench kann man dann in das kleine Suchfeld den Begriff "health" eingeben und dann das Healthcenter auswählen.
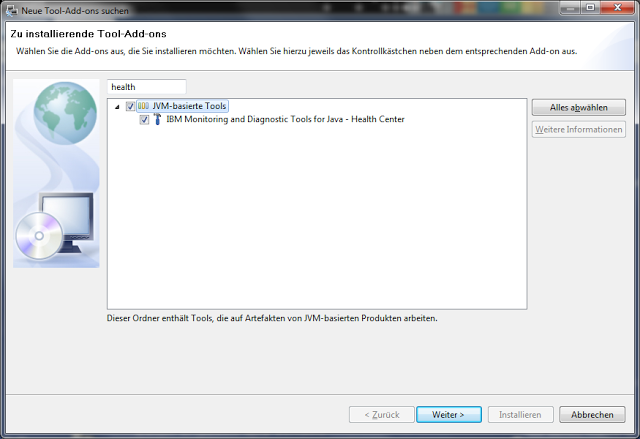
Danach wieder die Lizenzbedienungen abnicken und wenige Minuten später sollten auch die Addons installiert sein. Jetzt will die Workbench natürlich wieder einmal neu starten.
Nach dem Neustart ist die Workbench mit dem JVM Profiler soweit startklar.
Die Installation des Healthcenteragent in Lotus Notes und welche Einstellungen in Lotus Notes angepasst werden müssen damit der agent funktioniert, beschreibe ich dann in Teil 2.
Der erste Schritt ist, dass man falls man die IBM Support Assistance Workbench noch nicht hat, diese unter http://www-01.ibm.com/software/support/isa/ herunterlädt.
Der Inhalt der heruntergeladenen Datei muß nun in einen temporären Ordner entpackt werden.
Der temporäre Ordner sollte auf der gleichen Platte wie das Installationsziel sein, da sonst der Installer während der Installation abstürzt.
Im entpackten Ordner muß man dann die Datei "setupwin32.exe aufrufen.
Die Eula abnicken und solange weiter klicken, bis das Programm fertig installiert ist.
Danach sollte man wenn man mit einem Benutzer arbeitet, der auf das Programmverzeichnis keine Schreibrechte hat für die Workbench ausnahmsweise Schreibrechte vergeben. Der Updater der beim Starten der Anwendung läuft ist nicht schlau genug, dass er über die UAC höhere Rechte anfordert.
Jetzt kann man die Support Assistant Workbench starten. Den Anfangsassistenten kann man falls man nicht einen Proxy einstellen muß beherzt duchklicken. Es dauert dann etwas bis die Workbench sich aus der Updatesite im Internet die richtigen Updates gezogen hat.
Dann die Updates die er anbietet installieren, man braucht jedoch keine Produkt Addons installieren. Diese Seite einfach abbrechen.
Nach einiger Zeit sollte man dann die Meldung bekommen, dass die Workbench erfolgreich upgedated wurde.
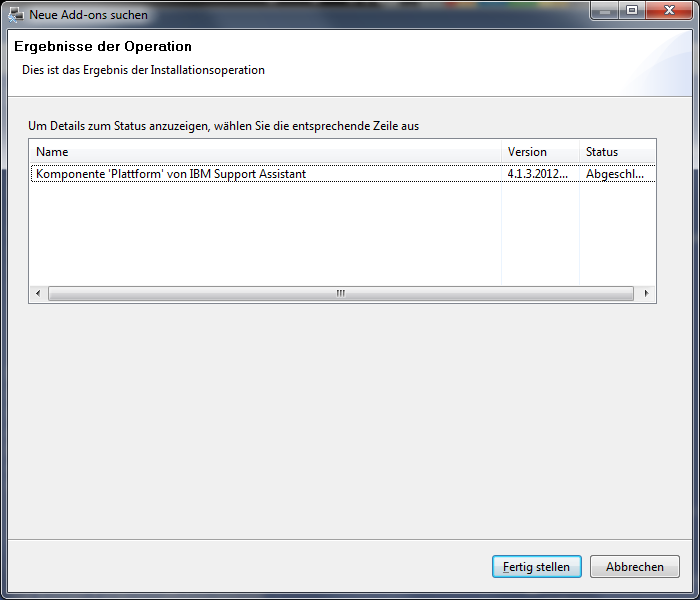
Nach dem Fertigstellung muss man dann noch einmal neustarten.
Jetzt kann man die JVM Healthcentertools in die Support Workbench installieren. Dazu muss man im Menü "Aktualisieren->Neue suchen..." den Punkte "Tool-Add-ons" aufrufen.
Nach einiger Nachdenkpause der Workbench kann man dann in das kleine Suchfeld den Begriff "health" eingeben und dann das Healthcenter auswählen.
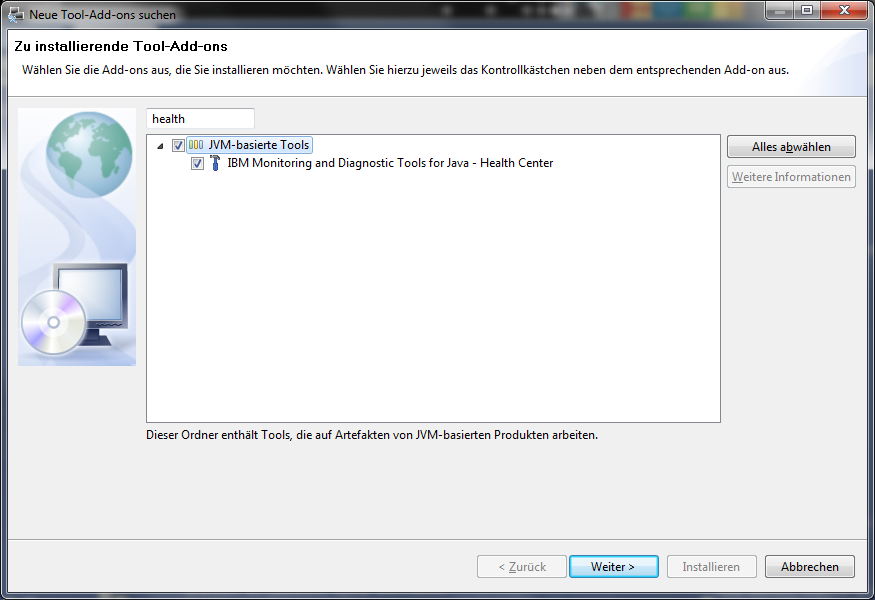
Danach wieder die Lizenzbedienungen abnicken und wenige Minuten später sollten auch die Addons installiert sein. Jetzt will die Workbench natürlich wieder einmal neu starten.
Nach dem Neustart ist die Workbench mit dem JVM Profiler soweit startklar.
Die Installation des Healthcenteragent in Lotus Notes und welche Einstellungen in Lotus Notes angepasst werden müssen damit der agent funktioniert, beschreibe ich dann in Teil 2.
Sunday, November 4, 2012
Java ist langsam, oder doch nicht?
In dem Beispiel erzeugen wir eine große SWT Tabelle wie es in vielen Anwendungen der Fall ist. Denken wir z.B. an eine Ansicht über den Kundenstamm. So eine Tabelle kann locker mal 100000 Einträge haben. Ich habe das ganze erst einmal so geschrieben, wie SWT Tabellen in den meisten Handbüchern erklärt werden. Zuerst wird ein Fenster erstellt. In dem Fenster die Tabelle und dann befülle ich über eine Schleife die Tabelle mit 100000 Zeilen. Das dauert auf meinem Rechner mit Quadcore CPU und reichlich Speicher unerträglich lange 15 Sekunden und zusätzlich zeigt mir der Systemmonitor einen Speicherverbrauch von unvorstellbaren 514 Megabyte für so ein simples Programm an.
Hier mal der Code wie es oft gemacht wird, man es aber bei größeren Tabellen auf keinen Fall machen sollte:
public class TestNormalTable {
public static void main(String[] args) {
Display display=new Display();
Shell shell=new Shell(display);
shell.setSize(600, 1024);
shell.setLayout(new FillLayout());
Table table=new Table(shell, SWT.BORDER);
table.setLinesVisible(true);
table.setHeaderVisible(true);
//Spalten erstellen.
{
TableColumn spalte=new TableColumn(table,SWT.NONE);
spalte.setText("Spalte 1");
spalte=new TableColumn(table,SWT.NONE);
spalte.setText("Spalte 2");
}
//Zeilen befüllen
for(int i=0;i<100000;i++){
TableItem zeile=new TableItem(table, SWT.NONE);
zeile.setText(0,"Beispieltext zeile ");
zeile.setText(1,new Integer(i).toString() );
}
//Spaltenbreiten optimieren.
for(TableColumn spalte:table.getColumns()){
spalte.pack();
}
shell.open();
while(!shell.isDisposed()){
if(!display.readAndDispatch()) display.sleep();
}
display.dispose();
}
}
Screenshot des erstellen Fensters.
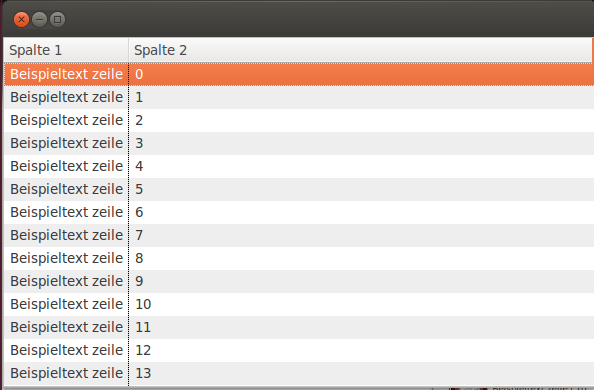
Bei oberflächlicher Betrachtung könnte man annehmen, dass Java einfach nicht schneller eine so simple Schleife mit 100.000 Wiederholungen durchlaufen kann. Wenn man das Programm aber durch einen Profiler schickt, dann sieht man sehr schnell, dass die verbrauchte Zeit und auch der verbrauchte Speicher gar nicht im Javacode steckt, sondern dass die meiste Zeit in nativen Code des Fenstertoolkit verschwendet wird. SWT zeichnet seine Komponenten zu denen auch die Tabelle gehört ja nicht selbst, sondern verwendet das native Fenstertoolkit der Plattform auf der das Programm läuft. In meinem Fall GTK+. Die Frage ist jetzt wie kann man vermeiden, dass bei einer so großen Tabelle alle nativen Tableitems erstellt werden müssen. Die Antwort ist ziemlich einfach und auch sehr effektiv. Man muss eine sogenannte Virtuelle SWT Tabelle verwenden.
Bei der virtuellen Tabelle wird die Tabelle mit dem style 'SWT.VIRTUAL' erstellt werden. Damit signalisiert man SWT, dass man eine Tabelle haben will, die dynamisch je nach Bedarf befüllt wird.
Hier mal der Code wie man eine hochperformante große Tabelle erstellt:
public class TestVirtualTable {
/**
* @param args
*/
public static void main(String[] args) {
final String[] spalte1=new String[100000];
final int[] spalte2=new int[100000];
Display display = new Display();
Shell shell = new Shell(display);
shell.setSize(600, 1024);
shell.setLayout(new FillLayout());
final Table table = new Table(shell, SWT.BORDER | SWT.VIRTUAL);
table.setLinesVisible(true);
table.setHeaderVisible(true);
//Arraytabelle befüllen.
for(int i=0;i<100000;i++){
spalte1[i]="Beispieltext zeile";
spalte2[i]=i;
}
// Spalten erstellen.
{
TableColumn spalte = new TableColumn(table, SWT.NONE);
spalte.setText("Spalte 1");
spalte = new TableColumn(table, SWT.NONE);
spalte.setText("Spalte 2");
}
// Grösse der Tabelle festlegen
table.setItemCount(100000);
// Callback Listener zum Auslesen der Daten hinzufügen.
// Immer wenn eine neue Zeile am Bildschirm angezeigt wird, wird dieser
// Listener aufgerufen um Daten anzufordern.
// Es werden also nur die Zeilen erstellt, die der Benutzer wirklich
// anschaut.
table.addListener(SWT.SetData, new Listener() {
@Override
public void handleEvent(Event event) {
TableItem zeile = (TableItem) event.item;
// Ermittelen des Zeilenindex. Im echten Leben würde man mit
// diesem Index z.B. auf ein Array zugreifen.
int index = table.indexOf(zeile);
zeile.setText(0, spalte1[index]);
zeile.setText(1, new Integer(spalte2[index]).toString());
}
});
// Spaltenbreiten optimieren.
// Da die virtuelle Tabelle erst nach dem Anzeigen befüllt wird, müssen
// wir die Spaltenbreitenoptimierung in die Eventwarteschlange hinten
// anfügen.
// Damit wird die Spaltenbreitenoptimierung nach dem Anzeigen der ersten
// Sätze ausgeführt und sollte schon gute Ergebnisse bringen.
Display.getDefault().asyncExec(new Runnable() {
@Override
public void run() {
for (TableColumn spalte : table.getColumns()) {
spalte.pack();
}
}
});
shell.open();
while (!shell.isDisposed()) {
if (!display.readAndDispatch())
display.sleep();
}
display.dispose();
}
}
Diese Version wird auf meinen Rechner praktisch verzögerungsfrei angezeigt. Zusätzlich belegt sie nur etwas über 34 Megabyte Hauptspeicher. Bei völlig gleichem Ergebnis.
Hier nocheinmal im Detail die wichtigen Punkte:
- Zeile 13 Die Tabelle mit dem style 'SWT.VIRTUAL' erstellen.
- Zeile 29 mit setItemCount der Tabelle mitteilen wie viele Items die Tabelle hat.
- Zeile 35-45 einen Listener der der Tabelle hinzufügen, der jedes mal aufgerufen wird, wenn die Tabelle neue Items darstellen will.
- Zeile 52-59 Da die Tabelle vor dem anzeigen noch keine Items hat, funktioniert der pack zum Festlegen der Spaltenbreite nicht, wenn man es wie im Code ohne Virtual macht. Ich setze daher den Code in ein Runnable dass ich mit asyncExec in die Eventqueue stelle. Dieser Code, wird dann nach dem Anzeigen der Tabelle ausgeführt. Dann hat die Tabelle schon die Items der ersten Seite und die Spaltenbreitenoptmierung wird dann anhand dieser Daten gemacht.
Wie man an diesen Beispiel sieht, können oft schon kleine Änderungen an einem Programm den Unterschied machen ob das Programm ein quälend langsamer Ressourcenfresser oder hochperformant und effizient ist. Ich verwende die virtuellen Tabellen übrigens z.B. in einem Programm zur Anzeige der Änderungen im Journal unserer DB2 durchgeführt werden. Wenn man da die Änderungen eines ganzen Tages aufruft, dann kommen schnell mal 2 Millionen Änderungen zusammen. Auch diese riesen Tabellen werden Dank SWT.VIRTUAL ohne Verzögerungen angezeigt.
Tuesday, August 21, 2012
JVM Profiler im JDK
Wenn man Programmcode optimieren will, ist es wichtig dass man weiß an welchen Stellen eine Optimierung des Codes wichtig ist. Man muß sozusagen die Hotspots im Code finden an denen die meiste Zeit vertrödelt wird. Dazu verwendet man sogennante Profiler die auf der einen Seite einen genauen Einblick in den Hauptspeicher eines laufenden Javaprogramms als auch eine genaue Analyse der Lauzeit und Häufigkeit der Verwendung von Methoden erlauben.
Man kann jetzt natürlich einen Profiler aus dem Internet herunterladen, aber zumindest seit Version 1.6 gibt es im JDK auch den sehr guten Java Visual VM im "bin" Verzeichnis. Da dieser auf jedem PC auf dem sich das JDK befindet installiert ist hat man immer schnell einen Profile bei der Hand.
Man kann jetzt natürlich einen Profiler aus dem Internet herunterladen, aber zumindest seit Version 1.6 gibt es im JDK auch den sehr guten Java Visual VM im "bin" Verzeichnis. Da dieser auf jedem PC auf dem sich das JDK befindet installiert ist hat man immer schnell einen Profile bei der Hand.
Monday, May 21, 2012
Performanceverbesserungen durch Indexonly Access beim Zugriff auf die DB/2
Sehr oft braucht man bei relationalen Zugriffen nicht den ganzen Datensatz sondern nur ein Feld. Ein typisches Beispiel ist der Kundenstamm. Meistens braucht man in Selects für die Anzeige nur den Kundennamen nicht aber den Rest der Informationen. In einer Auftragsanzeige könnte z.B. die Auftragsnummer, Kundennummer ,Kundenname, Artikelnummer angezeigt werden.
Das SQL Statement dafür wäre:
select auftraege.auftragsnummer, auftraege.kundennummer, kunden.kundenname, auftraege.artikelnummer from auftraege, kunden where auftraege.kundennummer=kunden.kundennummer
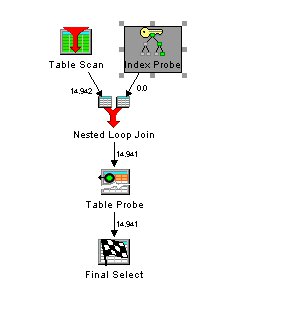
Um die Verarbeitung zu beschleunigen wurde ein Index über die Kundentabelle mit der kundennummer als Unique Key erstellt. Damit wird bei der Verarbeitung folgender Zugriffsplan verwendet:
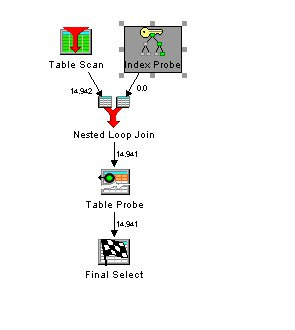 Die Auftragsdatei wird mittels Tablescan komplett durchgelesen. Für jeden Auftrag wird ein Index Zugriff durchgeführt und mit den Auftragen zusammengejoint. Dann muss aber noch für jeden Kunden ein extra Zugriff auf den Satz in der Kunden Tabelle erfolgen, um den Namen zu lesen. In unserer Beispieldatenbank sind weil wir 14.941 Aufträge haben dafür genau so viele Zugriffe notwendig.
Die Auftragsdatei wird mittels Tablescan komplett durchgelesen. Für jeden Auftrag wird ein Index Zugriff durchgeführt und mit den Auftragen zusammengejoint. Dann muss aber noch für jeden Kunden ein extra Zugriff auf den Satz in der Kunden Tabelle erfolgen, um den Namen zu lesen. In unserer Beispieldatenbank sind weil wir 14.941 Aufträge haben dafür genau so viele Zugriffe notwendig.
Wenn diese Abfrage in der Anwendung sehr oft verwendet wird, entsteht natürlich ein relativ großer Overhead. Dies kann man durch einen besseren Index, der die Verwendung von Index only Access erlaubt verbessert werden.
Wir ergänzen daher unseren Index und fügen hinter der kundennummer noch das Feld kundenname an.
Wenn wir nun die selbe SQL Anweisung wie oben ausführen, bekommen wir einen schnelleren Zugriffsplan:
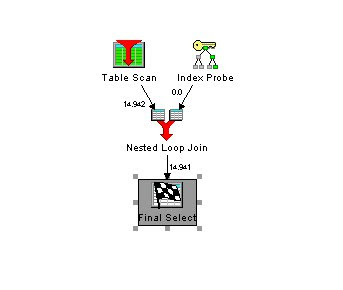
Die aufwendige Verarbeitung des Tableprobes ist komplett weggefallen. In den Erläuterungen zu dem Zugriffsplan steht auch, dass die Indexonly Methode für den Zugriff verwendet wurde.
Bei meinen Tests konnte ich eine 25% Performanceverbesserung des Query mit dem verbesserten Index gegenüber der ursprünglichen Variante feststellen.
Der Indexonly Zugriff beschleunigt nicht nur Joins sondern auch normale Zugriffe.
Das SQL:
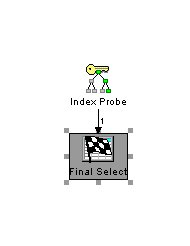
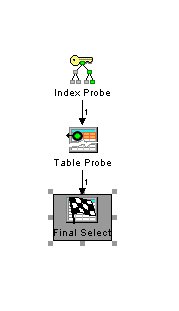
select kundenname from kunden where kundennummer=4711
wird wenn der um kundenname erweiterte Index vorhanden ist mit einem optimierten Zugriffsplan ausgeführt.
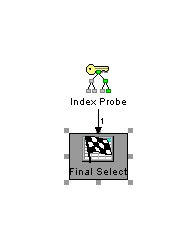 statt dem schlechteren Zugriffsplan wenn nur die kundenNummer im Index vorhanden ist.
statt dem schlechteren Zugriffsplan wenn nur die kundenNummer im Index vorhanden ist.
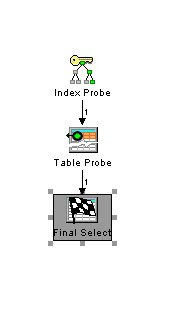 Die Tests wurden auf einen i/5 V6R1 durchgeführt. Sollten sich aber auf anderen Systemen ebenfalls nachvollziehen lassen. Einfach einmal ausprobieren.
Die Tests wurden auf einen i/5 V6R1 durchgeführt. Sollten sich aber auf anderen Systemen ebenfalls nachvollziehen lassen. Einfach einmal ausprobieren.
Das SQL Statement dafür wäre:
select auftraege.auftragsnummer, auftraege.kundennummer, kunden.kundenname, auftraege.artikelnummer from auftraege, kunden where auftraege.kundennummer=kunden.kundennummer
Um die Verarbeitung zu beschleunigen wurde ein Index über die Kundentabelle mit der kundennummer als Unique Key erstellt. Damit wird bei der Verarbeitung folgender Zugriffsplan verwendet:
Wenn diese Abfrage in der Anwendung sehr oft verwendet wird, entsteht natürlich ein relativ großer Overhead. Dies kann man durch einen besseren Index, der die Verwendung von Index only Access erlaubt verbessert werden.
Wir ergänzen daher unseren Index und fügen hinter der kundennummer noch das Feld kundenname an.
Wenn wir nun die selbe SQL Anweisung wie oben ausführen, bekommen wir einen schnelleren Zugriffsplan:
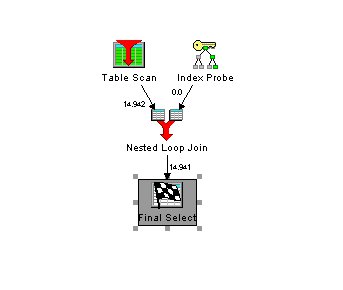
Die aufwendige Verarbeitung des Tableprobes ist komplett weggefallen. In den Erläuterungen zu dem Zugriffsplan steht auch, dass die Indexonly Methode für den Zugriff verwendet wurde.
Bei meinen Tests konnte ich eine 25% Performanceverbesserung des Query mit dem verbesserten Index gegenüber der ursprünglichen Variante feststellen.
Der Indexonly Zugriff beschleunigt nicht nur Joins sondern auch normale Zugriffe.
Das SQL:
select kundenname from kunden where kundennummer=4711
wird wenn der um kundenname erweiterte Index vorhanden ist mit einem optimierten Zugriffsplan ausgeführt.
Sunday, April 15, 2012
Performanceproblem bei getCount des ViewNavigators
In meinem letzten Post habe ich über die großen Performancegewinne bei Verwendung eines ViewNavigators bei iterieren über eine View geschrieben. (Link) Gerade bei RCP Anwendungen gibt es da jedoch einen kleinen Fallstrick.
Für die Anzeige des Fortschritts des Jobs benötigt man am Anfang die Gesamtanzahl der Dokumente die man verarbeiten möchte. Da würde einen als erstes die Methode getCount() von ViewNavigator ins Auge springen. Diese ist aber sehr langsam. Wenn man wirklich alle Dokumente der View verarbeitet sollte man lieber die getEntryCount() Methode der View verwenden. Falls man diese nicht verwenden kann, sollte man eventuell darüber nachdenken lieber einen unendlich Fortschrittsbalken zu verwenden.
Für die Anzeige des Fortschritts des Jobs benötigt man am Anfang die Gesamtanzahl der Dokumente die man verarbeiten möchte. Da würde einen als erstes die Methode getCount() von ViewNavigator ins Auge springen. Diese ist aber sehr langsam. Wenn man wirklich alle Dokumente der View verarbeitet sollte man lieber die getEntryCount() Methode der View verwenden. Falls man diese nicht verwenden kann, sollte man eventuell darüber nachdenken lieber einen unendlich Fortschrittsbalken zu verwenden.
Peformance Trick beim Durchlesen von Views
Eines vorweg für alle die mit Java auf Kriegsfuß stehen. Der Beispielcode ist zwar in Java. Das selbe sollte jedoch auch in anderen Sprachen z.B. Lotusscript funktionieren. Ich zeige dann am Ende des Posts den Code auch in Lotusscript versprochen
In vielen meiner Programme oder Agenten kommt Code vor, der alle Dokumente einer bestimmten View lesen und verarbeiten muss. wie z.B.
...
Document doc = view.getFirstDocument();
while (doc != null) {
Document tempdoc = doc;
//Mach irgendwas mit diesem doc
doc = view.getNextDocument(doc);
tempdoc.recycle();
}
...
Ausführungsdauer dieses Code bei unserer CRM Datenbank ca. 43 Sekunden.
Dabei war ich bis jetzt immer sehr enttäuscht über die Performance die Notes hier bietet. Das lesen von größeren Datenmengen dauert einfach ewig. Was hauptsächlich daran liegt, dass jeder Lesevorgang in der View eine Transaktion auslöst. Viel effizienter wäre es wenn Notes gleich ganze Blöcke lesen würde. Bisher gab es dazu keine Möglichkeit im Domino API. Bei der view gibt es das auch nach wie vor nicht. Aber im Rahmen der Performanceverbesserungen bei xPages wurden neue Features beim ViewNavigator eingeführt und die kann man sich hier zunutze machen.
Hier der selbe Code wie oben nur umgebaut auf die Verwendung eines ViewNavigators:
...
ViewNavigator navigator = view.createViewNav();
ViewEntry entry = navigator.getFirstDocument();
while (entry != null) {
Document doc = entry.getDocument();
//Mach irgendwas mit diesem doc
ViewEntry tempEntry = entry;
entry = navigator.getNextDocument();
tempEntry.recycle();
}
...
Das bringt natürlich noch keine Verbesserung des Laufzeitverhalten, sondern bringt sogar eine Verschlechterung auf 53 Sekunden.
Aber der ViewNavigator besitzt neue Methoden die ein geblocktes Lesen erlauben. Die Voraussetzung dafür ist einmal, dass man die View aus dem man den Navigator erstellt das Autoupdate abgewöhnt mit view.setAutoUpdate(false).
Dann kann man den ViewNavigator mit navigator.setBufferMaxEntries(x) mitteilen, dass man gerne x Sätze auf einmal lesen will. Dies verbessert die Performance enorm. (Update laut Domino Wiki darf der Wert x zwischen (2 und 400) sein. Ich habe festgestellt, dass höhere Werte als 400 eine leicht bessere performance bringen. Siehe auch Kommentag von Ulrich Krause)
Folgender Code von oben ergänzt mit Blocking läuft auf meiner Maschine in unter 10 Sekunden statt der 43 Sekunden im usprünglichen Code ohne Blocking.
...
view.setAutoUpdate(false);
ViewNavigator navigator = view.createViewNav();
navigator.setBufferMaxEntries(1024);
ViewEntry entry = navigator.getFirstDocument();
while (entry != null) {
Document doc = entry.getDocument();
//Mach irgendwas mit diesem doc
ViewEntry tempEntry = entry;
entry = navigator.getNextDocument();
tempEntry.recycle();
}
...
Das ist ja schon mal nicht schlecht.
Es gibt aber noch 2 zusätzliche Optionen mit denen man unter bestimmten Umständen noch zusätzliche Performance erzielen kann.
Wenn man wie in den obigen Beispiel die viewEntrys Spalten nicht benötigt, dann kann man das laden der Spaltenwerte unterdrücken. Je nach dem wie viele Spalten die View enthält, habe ich in meinem Tests nocheinmal eine Laufzeitreduktion um 10% erreichen können. Diese Option kann man mit navigator.setEntryOptions(ViewNavigator.VN_ENTRYOPT_NOCOLUMNVALUES) setzen.
Bei manchen Arten von Views kann es auch etwas bringen, die Entryoption navigator.setEntryOptions(ViewNavigator.VN_ENTRYOPT_NOCOUNTDATA); zu setzen. Laut meinen Informationen verhindert es die automatische Zählung bei kategorisierten Ansichten. Ich habe es aber noch nicht praktisch verwendet.
Noch einen zusätzlichen Performancegewinn, kann man erzielen, wenn man nur bestimmte Dokumente aus der View verarbeiten will, in dem man in der View die Selektionsfelder als Spalten aufnimmt, und dann das Dokument nur dann liest, wenn im Viewentry die Spaltenwerte den Selektionskriterien entsprechen. Hier sind die Performancegewinne noch stärker ausgeprägt als bei der klassischen Methode. Außerdem kann man natürlich noch die ganzen anderen Vorteile eines ViewNavigators verwenden. z.B. einen ViewNavigator mit allen Dokumenten einer bestimmten Kategorie einer kategorisierten View zu erstellen.
Hier noch wie am Anfang versprochen das oben angeführte Beispiel in Lotus script:
...
view.Autoupdate=false
Set navigator=view.Createviewnav()
navigator.Buffermaxentries=1024
navigator.Entryoptions=1 ' keine Spaltenwerte lesen.
Set entry=navigator.Getfirst()
While Not entry Is Nothing
Set doc=entry.Document
'Mach was mit dem Dokument
Set entry=navigator.Getnext(entry)
Wend
...
Würde mich über Kommentare zu den Performanceverbesserungen die Ihr in euren Anwendungen erzielen konntet freuen.
Subscribe to:
Posts (Atom)
ad