One of the biggest new features in IBM i 7.2 is Row and Column Access Control support in Db2 for IBM i. This feature allows you to control the access to specific rows and columns on user or group level. This is especially important when your users can access your database files with ODBC, JDBC, or File transfer, because with this methods the can bypass security features built into your application To get a smart start on the new possibilities this feature provides watch Mike Cain on youtube and read the new redpaper on redbooks.
Showing posts with label Db2. Show all posts
Showing posts with label Db2. Show all posts
Friday, September 12, 2014
Wednesday, April 16, 2014
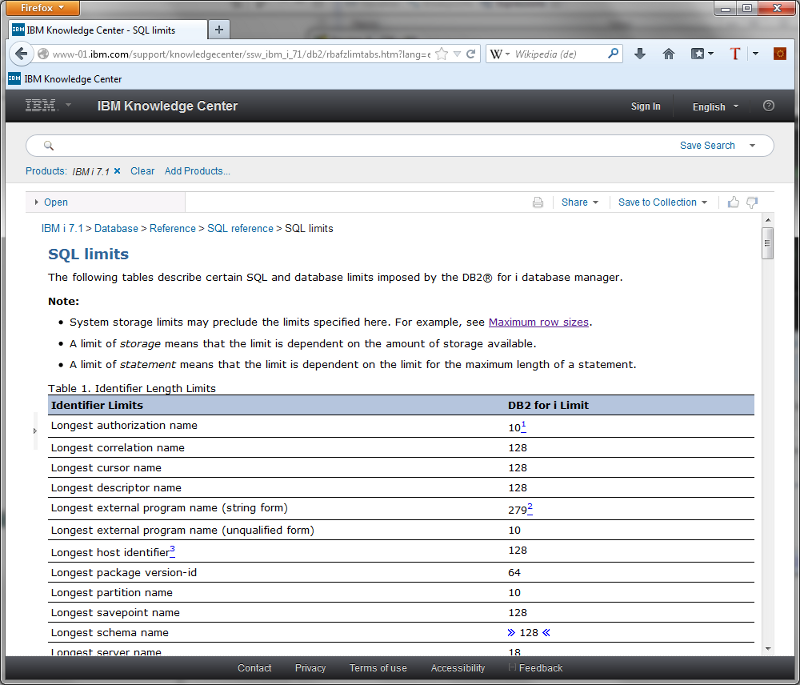
Limits of Db/2 in IBM i V7R1
Yes our mighty IBM i Db2 can really handle big databases, but everything in our universe is limited. So if you need to know the exact limits of Db2 on the IBM i you can find them in the new IBM knowledge center.
Wednesday, March 19, 2014
Improve SQL grouping performance with Db2 EVIs
In many SQL queries the "GROUP BY" clause is used to aggregate some values. For example a manager wants to see sales for a specific year grouped by region. The SQL for this query looks like this:
SELECT REGION, SUM(AMOUNT) FROM INVOICES WHERE YEAR=2013 GROUP BY REGION
The Db2 optimizer implements the query with a table scan and a temporary hash table.
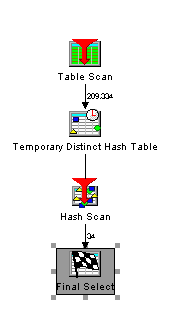
SELECT REGION, SUM(AMOUNT) FROM INVOICES WHERE YEAR=2013 GROUP BY REGION
The Db2 optimizer implements the query with a table scan and a temporary hash table.
Sunday, March 16, 2014
New Whitepaper: DDS and SQL - The Winning Combination for DB2 for i
If you are still using DDS and record level access in your "IBM i" applications you are missing most of the enhancements IBM has provided for "IBM i" since V5R1. While DDS and record level access are still supported and there are statements of directions that they will be supported in the future every "IBM i" Developer should really plan to migrate their applications from DDS to SQL.
 This migration is really very easy to do because it is more an evolution than a revolution. You can access DDS DB2 tables with SQL and you can access SQL DB2 tables with record level access. So you can write new programs with SQL while older programs are still using record level access. You can even mix SQL and record level access in one program without problems.
This migration is really very easy to do because it is more an evolution than a revolution. You can access DDS DB2 tables with SQL and you can access SQL DB2 tables with record level access. So you can write new programs with SQL while older programs are still using record level access. You can even mix SQL and record level access in one program without problems.
There are Wizards in IBM i Navigator to retrieve SQL DDL (Data Definition Language) sources from your DDS tables. When you convert tables and indexes from DDS to SQL you will get improved performance, because the SQL tables and indexes have an optimized page size.
Kent Milligan and Dave Hendrickson have provided a white paper which shows the advantages of SQL over DDS in detail. I really recommend this white paper to every "IBM i" application developer.

{kind=link}
There are Wizards in IBM i Navigator to retrieve SQL DDL (Data Definition Language) sources from your DDS tables. When you convert tables and indexes from DDS to SQL you will get improved performance, because the SQL tables and indexes have an optimized page size.
Kent Milligan and Dave Hendrickson have provided a white paper which shows the advantages of SQL over DDS in detail. I really recommend this white paper to every "IBM i" application developer.
Monday, July 29, 2013
New concurrent access resolution clauses in V7R1
In V6R1 and V7R1 IBM has added new very powerful clauses to control concurrent access resolution to the SQL language of the IBM i.
So what was wrong with concurrent access till V7R1. When a job changes some rows under commitment control, no other job can access this row even when this job only want to read the data for a query. The job has to wait until the blocking job commits his transaction. The query job can fail if the job reaches the access timeout before the blocking job has finished his transaction.
But now we have new possibilities to control the behavior in the query job.
New with V6R1 "SKIP LOCKED DATA"
When you add this clause to your select statement the query will ignore every row currently blocked by an uncommited transaction. In my opinion this option is not really an improvement, because with this clause you often get wrong results.
New with V7R1 "USE CURRENTLY COMMITED"
When you add this clause to your select statement the query will ignore uncommited changes, but will process the original values of the locked rows. So the result of the query, will be correct, and the query will not wait for record locks caused by open transactions.
For further informations and examples you can have a look at developer works
So what was wrong with concurrent access till V7R1. When a job changes some rows under commitment control, no other job can access this row even when this job only want to read the data for a query. The job has to wait until the blocking job commits his transaction. The query job can fail if the job reaches the access timeout before the blocking job has finished his transaction.
But now we have new possibilities to control the behavior in the query job.
New with V6R1 "SKIP LOCKED DATA"
When you add this clause to your select statement the query will ignore every row currently blocked by an uncommited transaction. In my opinion this option is not really an improvement, because with this clause you often get wrong results.
New with V7R1 "USE CURRENTLY COMMITED"
When you add this clause to your select statement the query will ignore uncommited changes, but will process the original values of the locked rows. So the result of the query, will be correct, and the query will not wait for record locks caused by open transactions.
For further informations and examples you can have a look at developer works
Sunday, July 28, 2013
Holiday reading: Analyze performance in DB2 on IBM i

OnDemand SQL Performance Analysis Simplified on DB2 for i5/OS
To get up to date you can read the DB2 section of the following two redbooks.
IBM i 6.1 Technical Overview
IBM i 7.1 Technical Overview with Technology Refresh Updates
Wednesday, June 12, 2013
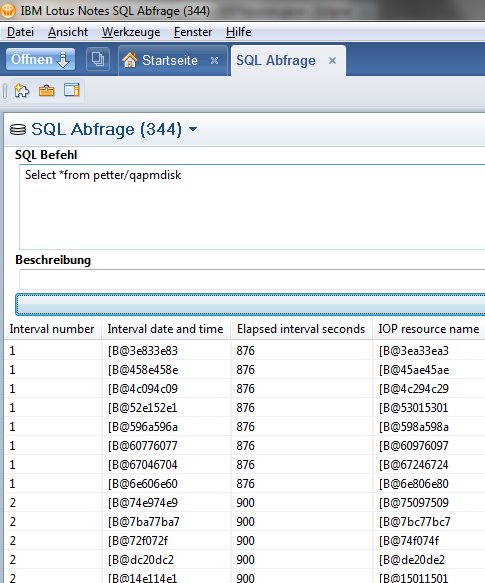
Read Character Columns with CCSID 65535 in JDBC
In DB2 on the System i every Character Column have a CCSID which defines with which characterset the data of this column is encoded. For example a column with german characters should normally be encoded with 273 or 1141. When you access this columns from JDBC the data will be automatically converted from the characterset used in the column to Unicode. But when the CCSID of the column is 65535 (binary data) the jdbc driver will not convert and since all data on the System i is stored in EBCDIC you will only get garbage from this columns.
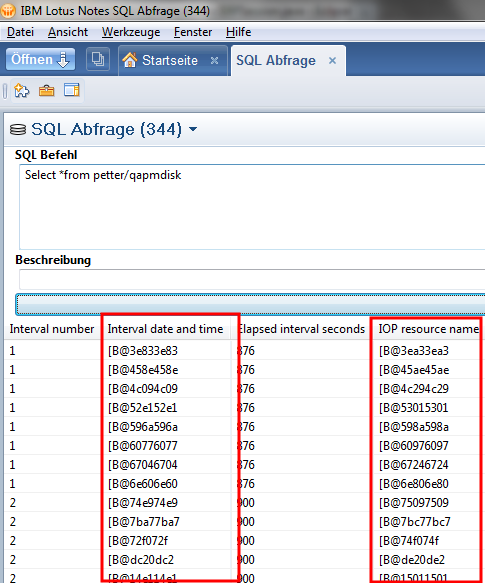
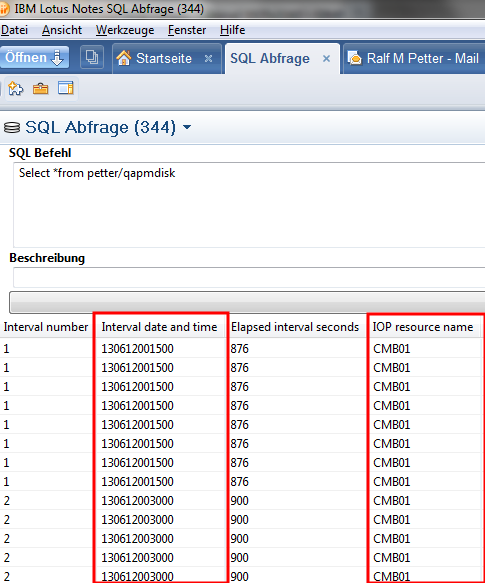
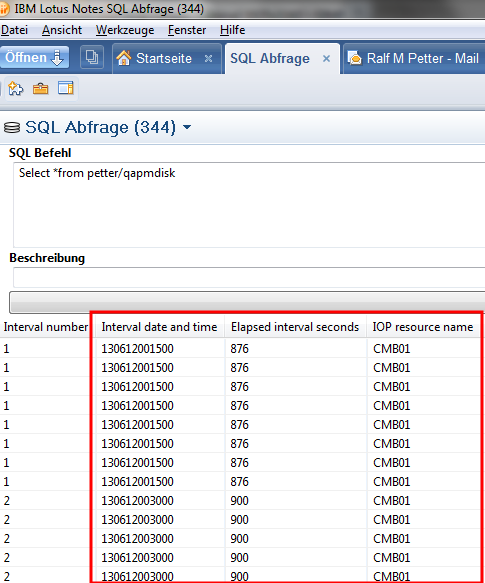
But there is an easy way to fix this problem. You need to set the translateBinary Option to true when you connect to your System i and every 65535 character field will be translated from EBCDIC to Unicode automatically.
Then the result is human readable.
{kind=link}
{kind=link}
But there is an easy way to fix this problem. You need to set the translateBinary Option to true when you connect to your System i and every 65535 character field will be translated from EBCDIC to Unicode automatically.
AS400JDBCDataSource dataSource = new AS400JDBCDataSource(systemName, userName, password);
dataSource.setTranslateBinary(true);
Connection conn = dataSource.getConnection();
// Or when you prefer the old connection Method
Connection conn2 = DriverManager.getConnection("jdbc:as400://" + systemName + ";translate binary=true",
userName, password);
Then the result is human readable.
Monday, June 10, 2013
Add a column to a DB2 table in a specific position in V7R1
With the SQL command "ALTER TABLE" you are able to add columns to your DB2 Tables for a long time. But before V7R1 you can only add columns to the end of the row. In V7R1 you can use the "BEFORE column" clause to specify the exact position where your new column should be inserted. Here is an example:
Table "customer"
With "ALTER TABLE customer ADD COLUMN Customer_Name2 CHAR(30) BEFORE Customer_address" can you add a second name column to the correct position.
Table "customer"
| Field | Type |
| Customer_Number | CHAR(10) |
| Customer_Name1 | CHAR(30) |
| Customer_address | CHAR(30) |
With "ALTER TABLE customer ADD COLUMN Customer_Name2 CHAR(30) BEFORE Customer_address" can you add a second name column to the correct position.
Saturday, June 8, 2013
Visual Explain explained
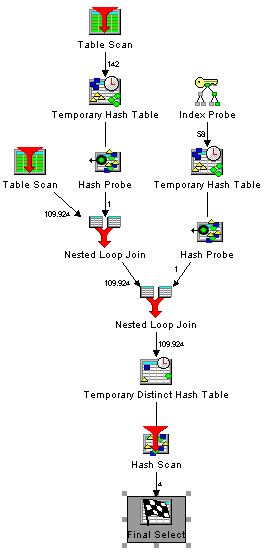
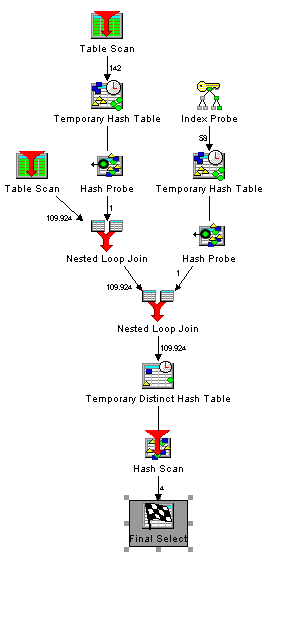
Visual Explain in Db2 is a great tool which shows you how the query optimizer actually processes your sql statements. It gives you every information that you need to improve your sql statements or gives you hints which indexes you should create to get a better performance. Here is an example of the output of visual explain:
{kind=link}
Every little icon represents one process step in your query. Some of the icons are pretty clear. Everyone knows what a table scan or and index probe means. But what about the others? The online help of Visual explain is not really helpfull, because there are only very short descriptions of every icon. But fortunatly there is a detailed description with examples of every access method the query optimizer can choose to process your sql statements in the IBM i information center. If you prefer to read this informations on paper you can download a PDF from http://pic.dhe.ibm.com/infocenter/iseries/v7r1m0/topic/rzajq/rzajq.pdf
Sunday, April 14, 2013
Howto get auto generated values from rows created by SQL inserts in DB2
Normally you know exactly which values are in the columns of a newly inserted row in a database table. But when your table has an automatic generated identity column which is the primary key of the table you will want the automatic generated key value from your insert statement. But the normal insert command does not give back values. Fortunatly newer DB2 Version have the "Select from final Table" clause to solve the problem.
For example we have an address table created by the following commands:
CREATE TABLE PETTER/ADRESSEN (
"KEY" INTEGER GENERATED ALWAYS AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER
CACHE 20 ),
NAME1 CHAR(20) CCSID 273 NOT NULL ,
NAME2 CHAR(20) CCSID 273 NOT NULL ) ;
LABEL ON COLUMN PETTER/ADRESSEN
( "KEY" TEXT IS 'Primary Key' ,
NAME1 TEXT IS 'Name1' ,
NAME2 TEXT IS 'Name2' ) ;
And here is the code to add a row and get the automatic created identity number back in one step.
With the "Select from final table" clause you can retrieve values which are set by trigger prgograms or other advanced Db2 features too.
For example we have an address table created by the following commands:
CREATE TABLE PETTER/ADRESSEN (
"KEY" INTEGER GENERATED ALWAYS AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER
CACHE 20 ),
NAME1 CHAR(20) CCSID 273 NOT NULL ,
NAME2 CHAR(20) CCSID 273 NOT NULL ) ;
LABEL ON COLUMN PETTER/ADRESSEN
( "KEY" TEXT IS 'Primary Key' ,
NAME1 TEXT IS 'Name1' ,
NAME2 TEXT IS 'Name2' ) ;
And here is the code to add a row and get the automatic created identity number back in one step.
PreparedStatement ps = con
.prepareStatement("Select * from final table (Insert into petter/adressen( name1,name2) values('Ralf','Petter'))");
ResultSet rs = ps.executeQuery();
rs.next();
System.out.println(rs.getBigDecimal(1));
With the "Select from final table" clause you can retrieve values which are set by trigger prgograms or other advanced Db2 features too.
Thursday, April 11, 2013
Howto split a String with a delimiter in SQL
Today i want to show how to split a String with a delimiter in SQL for example in a table with modelnumbers which consists of two parts sperated by a slash.
model
A1/44
CX3/2
C/140
To get the first and second part of the modelnumber you can use
select LEFT( trim(model),LENGTH(trim(model))-ABS(LOCATE('/',trim(model))-1)) model1, RIGHT( trim(model), LENGTH(trim(model))-LOCATE('/',trim(model))) model2 from modeltable
to get the result:
model1 model2
A1 44
CX3 2
C 140
model
A1/44
CX3/2
C/140
To get the first and second part of the modelnumber you can use
select LEFT( trim(model),LENGTH(trim(model))-ABS(LOCATE('/',trim(model))-1)) model1, RIGHT( trim(model), LENGTH(trim(model))-LOCATE('/',trim(model))) model2 from modeltable
to get the result:
model1 model2
A1 44
CX3 2
C 140
Thursday, December 27, 2012
Hochperformante und sichere SQL Zugriffe in Java
Beim Zugriff auf SQL Datenbanken wird immer gerne der Fehler gemacht, dass wenn ein SQL Statement mehrmals mit verschiedenen Parametern ausgeführt werden soll nicht die dafür vorgesehenen PreparedStatements sondern die SQL Befehle mit String Konkatinierung zusammengebaut und mit execute() ausgeführt werden. Sogar in Java Lehrbüchern findet man immer wieder Beispiele wie das folgende, dass man aber in der Praxis auf keinen Fall so verwenden sollte.
Es gibt zwei Gründe warum man seinen SQL Code nicht jedes mal als String zusammenbauen und dann mit execute() ausführen soll.
Bei wiederholter Ausführung des selben SQL Code ist die Performance viel besser, wenn der SQL Code nicht jedesmal geparst, geprüft und in einen Zugriffsplan übersetzt werden muß. Der Vorgang ein SQL Kommando in einen Zugriffsplan zu übersetzen ist je nach verwendeter Datenbank und Komplexität der Anweisung extrem aufwendig. Der oben angeführte Codeblock in dem die Zeit gemessen wird, läuft wenn man Preparedstatements verwendet, ca. 3 mal schneller als mit dem oben angeführten Code.
Was aber fast noch wichtiger ist, wenn ich SQL Befehle mit String Konkatinierung zusammenbaue, dann wird der Code anfällig für SQL Injections. Das heißt, es kann in der Variable mit ein paar Tricks beliebiger SQL Code eingeschleust werden. Dies ist eine der häufigsten Einfallstore für Hacks auf Webseiten. Also selbst wenn ein Statement nur einmal verwendet wird, sollte man auf jeden Fall um SQL Injections zu vermeiden Preparedstatements verwenden.
Noch dazu ist die Verwendung von Preparedstatements eigentlich extrem einfach. Man ändert den Typ von stmt auf PreparedStatement, und erstellt das Objekt mit prepareStatement(). Für jeden Wert der in der Anweisung variabel sein soll fügt man ein Fragezeichen ein. Der sqlCode aus obigen Beispiel heißt dann "select * from adressen where adnr=?". Bei jeder Verwendung der SQL Anweisung muss dann mit der passenden set Methode der Platzhalter im Statement mit dem richtigen Wert befüllt werden. Am leichtesten zu verstehen ist es wenn man sich folgendes Beispiel anschaut.
Die Preparedstatements können natürlich nicht nur für "Selects", sondern genauso gut auch für "Inserts" und "Updates" verwendet werden.
Wer JDBC Zugriffe in seinen xPages, Plugins oder Agenten verwendet, sollte prüfen ob er auch wirklich überall schon PreparedStatements verwendet. Der Performancegewinn und vor allem die zusätzliche Sicherheit vor SQL Injections sollte den geringen Änderungsaufwand auf jeden Fall lohnen.
public class StatementJDBC {
private static Statement stmt;
/**
* @param args
*/
public static void main(String[] args) {
//Verbinde mit Datenbank und initalisiere Anweisung
AS400JDBCDataSource dataSource = new AS400JDBCDataSource("localhost", "user", "password");
try {
Connection con=dataSource.getConnection();
stmt=con.createStatement();
//Gib verschiedene Namen aus der Adressdatei mit verschiedenen Adressnummern aus.
Date start=new Date();
System.out.println(getName("40"));
System.out.println(getName("41"));
System.out.println(getName("42"));
System.out.println(getName("43"));
System.out.println(new Date().getTime()-start.getTime());
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* Liest mittels SQL den Namen eines Adressatzes.
*
* Hier wird jedes mal ein SQLStatement mit String Konkatinierung zusammengebaut
* und ausgeführt.
*
* Dies soll man in der Praxis nicht machen.
* @param adressNummer
* @return Name
*/
private static String getName(String adressNummer) throws SQLException {
ResultSet rs=stmt.executeQuery("select * from adressen where adnr="+adressNummer);
if(rs.next()) return rs.getString("adnam1");
return "";
}
}
Es gibt zwei Gründe warum man seinen SQL Code nicht jedes mal als String zusammenbauen und dann mit execute() ausführen soll.
Bei wiederholter Ausführung des selben SQL Code ist die Performance viel besser, wenn der SQL Code nicht jedesmal geparst, geprüft und in einen Zugriffsplan übersetzt werden muß. Der Vorgang ein SQL Kommando in einen Zugriffsplan zu übersetzen ist je nach verwendeter Datenbank und Komplexität der Anweisung extrem aufwendig. Der oben angeführte Codeblock in dem die Zeit gemessen wird, läuft wenn man Preparedstatements verwendet, ca. 3 mal schneller als mit dem oben angeführten Code.
Was aber fast noch wichtiger ist, wenn ich SQL Befehle mit String Konkatinierung zusammenbaue, dann wird der Code anfällig für SQL Injections. Das heißt, es kann in der Variable mit ein paar Tricks beliebiger SQL Code eingeschleust werden. Dies ist eine der häufigsten Einfallstore für Hacks auf Webseiten. Also selbst wenn ein Statement nur einmal verwendet wird, sollte man auf jeden Fall um SQL Injections zu vermeiden Preparedstatements verwenden.
Noch dazu ist die Verwendung von Preparedstatements eigentlich extrem einfach. Man ändert den Typ von stmt auf PreparedStatement, und erstellt das Objekt mit prepareStatement(). Für jeden Wert der in der Anweisung variabel sein soll fügt man ein Fragezeichen ein. Der sqlCode aus obigen Beispiel heißt dann "select * from adressen where adnr=?". Bei jeder Verwendung der SQL Anweisung muss dann mit der passenden set Methode der Platzhalter im Statement mit dem richtigen Wert befüllt werden. Am leichtesten zu verstehen ist es wenn man sich folgendes Beispiel anschaut.
public class PreparedStatementJDBC {
private static PreparedStatement stmt;
/**
* @param args
*/
public static void main(String[] args) {
//Verbinde mit Datenbank und initalisiere Anweisung
AS400JDBCDataSource dataSource = new AS400JDBCDataSource("localhost", "user", "password");
try {
Connection con=dataSource.getConnection();
stmt=con.prepareStatement("select * from adressen where adnr=?");
//Gib verschiedene Namen aus der Adressdatei mit verschiedenen Adressnummern aus.
Date start=new Date();
System.out.println(getName("40"));
System.out.println(getName("41"));
System.out.println(getName("42"));
System.out.println(getName("43"));
System.out.println(new Date().getTime()-start.getTime());
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* Liest mittels SQL den Namen eines Adressatzes.
* @param adressNummer
* @return Name
*/
private static String getName(String adressNummer) throws SQLException {
//Parameter im vorbereiteten Statement setzen.
stmt.setInt(1, new Integer(adressNummer).intValue());
ResultSet rs=stmt.executeQuery();
if(rs.next()) return rs.getString("adnam1");
return "";
}
}
Die Preparedstatements können natürlich nicht nur für "Selects", sondern genauso gut auch für "Inserts" und "Updates" verwendet werden.
Wer JDBC Zugriffe in seinen xPages, Plugins oder Agenten verwendet, sollte prüfen ob er auch wirklich überall schon PreparedStatements verwendet. Der Performancegewinn und vor allem die zusätzliche Sicherheit vor SQL Injections sollte den geringen Änderungsaufwand auf jeden Fall lohnen.
Monday, May 21, 2012
Performanceverbesserungen durch Indexonly Access beim Zugriff auf die DB/2
Sehr oft braucht man bei relationalen Zugriffen nicht den ganzen Datensatz sondern nur ein Feld. Ein typisches Beispiel ist der Kundenstamm. Meistens braucht man in Selects für die Anzeige nur den Kundennamen nicht aber den Rest der Informationen. In einer Auftragsanzeige könnte z.B. die Auftragsnummer, Kundennummer ,Kundenname, Artikelnummer angezeigt werden.
Das SQL Statement dafür wäre:
select auftraege.auftragsnummer, auftraege.kundennummer, kunden.kundenname, auftraege.artikelnummer from auftraege, kunden where auftraege.kundennummer=kunden.kundennummer
Um die Verarbeitung zu beschleunigen wurde ein Index über die Kundentabelle mit der kundennummer als Unique Key erstellt. Damit wird bei der Verarbeitung folgender Zugriffsplan verwendet:
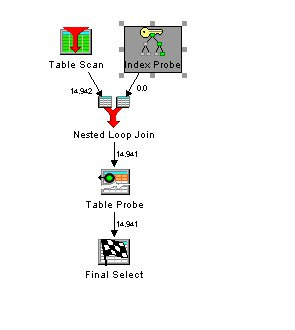 Die Auftragsdatei wird mittels Tablescan komplett durchgelesen. Für jeden Auftrag wird ein Index Zugriff durchgeführt und mit den Auftragen zusammengejoint. Dann muss aber noch für jeden Kunden ein extra Zugriff auf den Satz in der Kunden Tabelle erfolgen, um den Namen zu lesen. In unserer Beispieldatenbank sind weil wir 14.941 Aufträge haben dafür genau so viele Zugriffe notwendig.
Die Auftragsdatei wird mittels Tablescan komplett durchgelesen. Für jeden Auftrag wird ein Index Zugriff durchgeführt und mit den Auftragen zusammengejoint. Dann muss aber noch für jeden Kunden ein extra Zugriff auf den Satz in der Kunden Tabelle erfolgen, um den Namen zu lesen. In unserer Beispieldatenbank sind weil wir 14.941 Aufträge haben dafür genau so viele Zugriffe notwendig.
Wenn diese Abfrage in der Anwendung sehr oft verwendet wird, entsteht natürlich ein relativ großer Overhead. Dies kann man durch einen besseren Index, der die Verwendung von Index only Access erlaubt verbessert werden.
Wir ergänzen daher unseren Index und fügen hinter der kundennummer noch das Feld kundenname an.
Wenn wir nun die selbe SQL Anweisung wie oben ausführen, bekommen wir einen schnelleren Zugriffsplan:
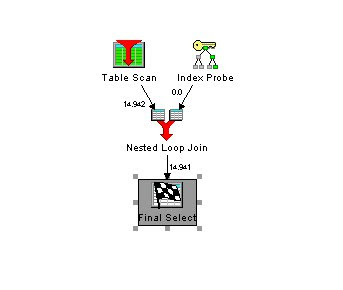
Die aufwendige Verarbeitung des Tableprobes ist komplett weggefallen. In den Erläuterungen zu dem Zugriffsplan steht auch, dass die Indexonly Methode für den Zugriff verwendet wurde.
Bei meinen Tests konnte ich eine 25% Performanceverbesserung des Query mit dem verbesserten Index gegenüber der ursprünglichen Variante feststellen.
Der Indexonly Zugriff beschleunigt nicht nur Joins sondern auch normale Zugriffe.
Das SQL:
select kundenname from kunden where kundennummer=4711
wird wenn der um kundenname erweiterte Index vorhanden ist mit einem optimierten Zugriffsplan ausgeführt.
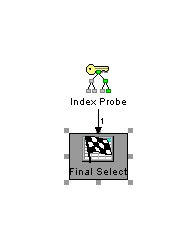 statt dem schlechteren Zugriffsplan wenn nur die kundenNummer im Index vorhanden ist.
statt dem schlechteren Zugriffsplan wenn nur die kundenNummer im Index vorhanden ist.
 Die Tests wurden auf einen i/5 V6R1 durchgeführt. Sollten sich aber auf anderen Systemen ebenfalls nachvollziehen lassen. Einfach einmal ausprobieren.
Die Tests wurden auf einen i/5 V6R1 durchgeführt. Sollten sich aber auf anderen Systemen ebenfalls nachvollziehen lassen. Einfach einmal ausprobieren.
Das SQL Statement dafür wäre:
select auftraege.auftragsnummer, auftraege.kundennummer, kunden.kundenname, auftraege.artikelnummer from auftraege, kunden where auftraege.kundennummer=kunden.kundennummer
Um die Verarbeitung zu beschleunigen wurde ein Index über die Kundentabelle mit der kundennummer als Unique Key erstellt. Damit wird bei der Verarbeitung folgender Zugriffsplan verwendet:
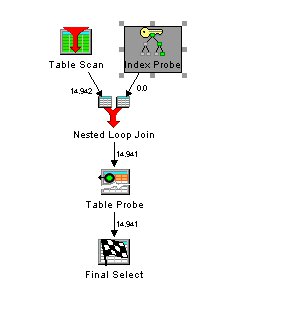
Wenn diese Abfrage in der Anwendung sehr oft verwendet wird, entsteht natürlich ein relativ großer Overhead. Dies kann man durch einen besseren Index, der die Verwendung von Index only Access erlaubt verbessert werden.
Wir ergänzen daher unseren Index und fügen hinter der kundennummer noch das Feld kundenname an.
Wenn wir nun die selbe SQL Anweisung wie oben ausführen, bekommen wir einen schnelleren Zugriffsplan:
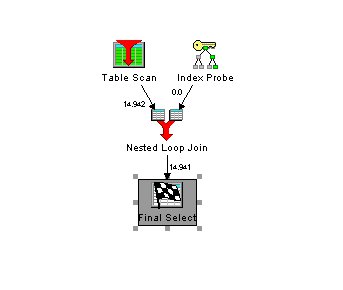
Die aufwendige Verarbeitung des Tableprobes ist komplett weggefallen. In den Erläuterungen zu dem Zugriffsplan steht auch, dass die Indexonly Methode für den Zugriff verwendet wurde.
Bei meinen Tests konnte ich eine 25% Performanceverbesserung des Query mit dem verbesserten Index gegenüber der ursprünglichen Variante feststellen.
Der Indexonly Zugriff beschleunigt nicht nur Joins sondern auch normale Zugriffe.
Das SQL:
select kundenname from kunden where kundennummer=4711
wird wenn der um kundenname erweiterte Index vorhanden ist mit einem optimierten Zugriffsplan ausgeführt.
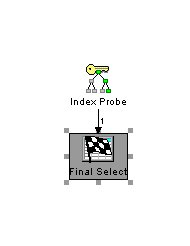
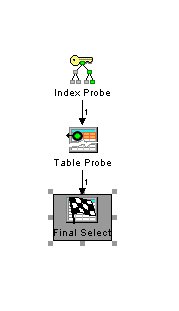
Subscribe to:
Posts (Atom)
ad